Python上课笔记汇总
1 入门
1.1 概述
1.1.1 Python简介
发音:英[ˈpaiθən],美[ˈpaiθaːn]
结合了解释性、编译性、互动性和面向对象的脚本语言
支持命令式编程、函数式编程和面向对象程序设计
由荷兰人Guido van Rossum于1989年发明,第一个公开版本发行于1991年
已经成为最受欢迎的程序设计语言之一
自2004年以后,Python的使用率呈线性增长
2011年1月,Python被TIOBE编程语言排行榜评为2010年度编程语言
2017年7月20日,IEEE spectrum发布了第四届顶级编程语言交互排行榜,Python高居首位
具有简洁性、易读性和可扩展性
在国外用Python做科学计算的研究机构日益增多
一些世界著名大学已经采用Python来教授程序设计课程,如卡耐基梅隆大学的编程基础、麻省理工学院的计算机科学及编程导论就使用Python讲授
众多开源的科学计算库都提供了Python的调用接口,如著名的计算机视觉库OpenCV、三维可视化库VTK、医学图像处理库ITK等
专用的第三方库也很多,如科学计算库NumPy、SciPy、Pandas分别提供了快速数组处理、科学计算和数据分析功能
1.1.2 Python特点
🚀 Python的优势
- 简单、易学
- 可移植性
- 解释性
- 面向对象
- 可扩展性和可嵌入性
- 丰富的库和模块
🚀 Python的局限性
不足和局限性。和C、C++等程序设计语言相比,Python程序运行速度较慢
对于运行速度高的程序,可以将运行速度要求较高的部分使用C、C++等编写,再将其嵌入Python中,充分发挥不同语言的特长和优势
现在计算机硬件的配置不断提高,在大多数情况下,程序运行速度并不是考虑的首要问题
1.1.3 Python应用
常规软件开发
科学计算与数据分析
网络爬虫
Web应用开发
系统网络运维
人工智能与机器学习
1.2 开发环境
1.2.1 Python版本
目前有两个不同序列的版本:Python 2.X和Python 3.X
两个序列的版本很多用法不兼容,内置函数和标准库模块用法也有较大的差别,适用于这两个版本的第三方库的差别更大,Python开发团队重申了终止对 Python 2.X的支持, 本书所有程序均基于Windows平台下的Python 3.X版本
1.2.2 常用开发环境
🚀 常用
- Python自带的开发工具
- PyCharm
🚀 其它
Anaconda3
Vim
Sublime Text
PythonWin
1.2.3 Python下载和安装
🚀 Python
无脑安装,勾选
Add Python x.x To Path,选择Customize installation自定义安装
🚀 安装测试
win+R输入cmd执行python测试环境.exit或quit退出环境
C:\Users\86158>python |
1.2.4 PyCharm下载和安装
🚀 PyCharm
由JetBrains公司打造的一款Python IDE。帮助用户开发时提高其效率的工具,如调试、语法高亮、Project管理、代码跳转等。提供了一些高级功能,以支持Django框架下的专业Web开发。有Professional和Community两种版本
🚀 PyCharm 下载
Pycharm官网,官网试用三十天,小张是从软件管家下的,懂得都懂!
1.2.5 第三方库安装
多种方法,三选一
🚀 使用pip命令直接安装NumPy
win+R输入cmd进入命令行界面,输入命令,安装NumPy。
python -m pip install numpy scipy matplotlib ipython jupyter pandas sympy nose -i https://pypi.douban.com/simple/ |
🚀 使用pip命令运行NumPy安装文件
NumPy官网,同理在cmd中,切到Numpy文件路径下,输入命令pip install numpy-1.22.2-pp38-pypy38_pp73-manylinux_2_17_x86_64.manylinux2014_x86_64.whl(自己的文件名字)安装NumPy
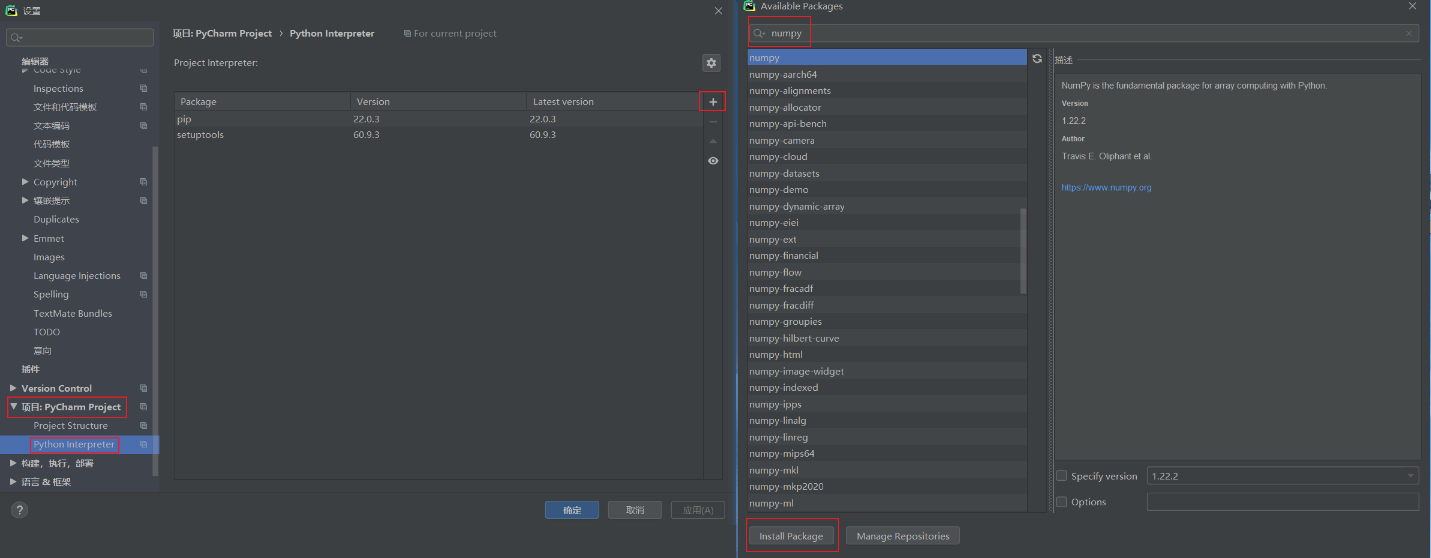
🚀 在PyCharm中下载安装NumPy
打开PyCharm,File→Settings→PyCharm Project→Python Interpreter(文件→设置→PyCharm Project→Python Interpreter)
1.3 程序开发
1.3.1 程序运行方式
🚀 Python程序可以在交互模式和脚本模式下运行
交互模式运行。用于程序功能简单、代码较少的程序
脚本模式运行。用于功能复杂、代码量较大的程序
1.3.2 使用Python自带工具开发Python程序
🚀 两种方式
Windows命令行方式
IDLE方式
🚁 Windows命令行方式 交互模式
win+R输入cmd进入命令行界面,输入python,回车进入运行环境
Microsoft Windows [版本 10.0.19044.1526] |
🚁 Windows命令行方式 脚本模式
使用记事本编写Python源文件,保存程序代码,文件名为hello.py
#file: hello.py |
win+R输入cmd进入命令行界面,输入python 文件路径路径\hello.py,输出
Hello,World! |
🚁 IDLE方式 交互模式
IDLE是Python内置的集成开发环境,由Python安装包提供,是Python自带的文本编辑器
开始→Python x.x→IDLE进入Shell开发环境
Python 3.9.10 (tags/v3.9.10:f2f3f53, Jan 17 2022, 15:14:21) [MSC v.1929 64 bit (AMD64)] on win32 |
🚁 IDLE方式 脚本模式
开始→Python x.x→IDLE进入Shell开发环境,File→New File打开空白源代码编辑窗口
#file: hello.py |
File→Save As,选择保存源文件路径,输入名称hello.py单击保存,Run→Run Module F5
Python 3.9.10 (tags/v3.9.10:f2f3f53, Jan 17 2022, 15:14:21) [MSC v.1929 64 bit (AMD64)] on win32 |
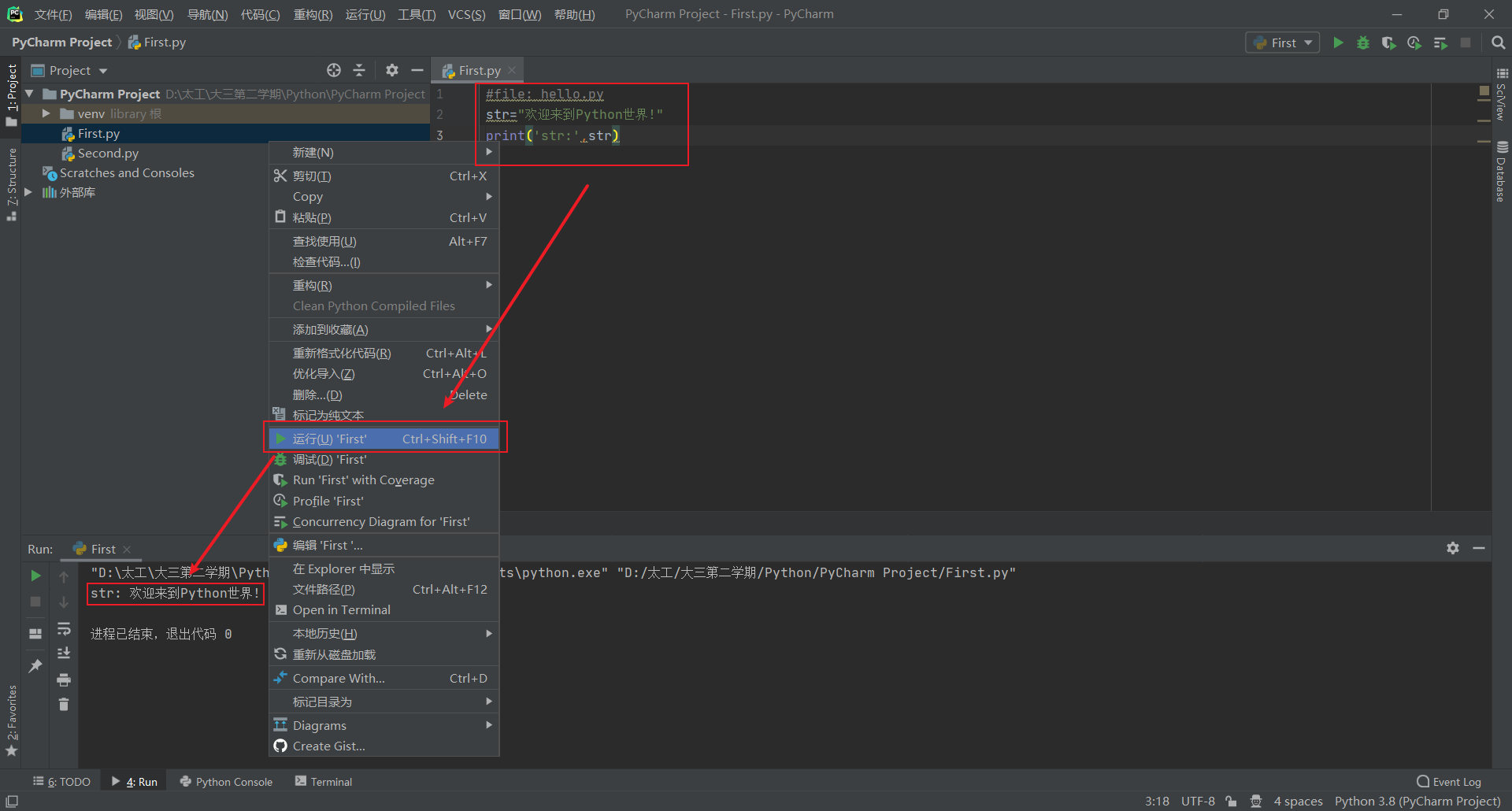
1.3.3 使用PyCharm开发Python程序
Create New Project→Pure Python填写文件路径,右击新建的工程,New→Python File填写文件名字

编写代码,右击文件名点击运行即可
#file: hello.py |
1.4 程序结构和编码规范
1.4.1 文件类型
在Python中,常用的文件类型有3种:源代码文件、字节代码文件、优化代码文件
🚀 源代码文件
- 源代码文件
- 扩展名为.py
- 使用文本编辑器编辑
🚀 字节代码文件
- 扩展名为.pyc
- 由Python源代码文件编译而成的二进制文件
- 由Python加速执行,速度快,能够隐藏源代码
- 可以通过python.exe或脚本方式将Python源文件编译成Python字节代码文件
🚀 优化代码文件
- 优化编译后的文件
- 无法用文本编辑器进行编辑
- 一般用于嵌入式系统
1.4.2 代码结构
import math |
一个完整的Python程序一般包括如下部分:
- 导入模块。代码第1行
- 定义函数。代码第2~5行
- 定义变量或常量。代码第7~9行
- 输入:代码第7~8行
- 处理:代码第9行
- 输出:代码第10行
- 注释:代码第2行和程序代码中其他以#开头的部分
__name__:代码第6行
1.4.3 程序编码规范
🚀 标识符
在Python中,用来给类、对象、方法、变量、接口和自定义数据类型等命名的名称
Python标识符由数字、字母、汉字和下画线_组成。遵循如下规则:
- 标识符必须以字母、汉字或下画线开头
- 标识符不能使用空格或标点符号(如括号、引号、逗号等)
- 不能使用Python关键字作为标识符,如关键字if不能作为标识符
- 不建议使用模块名、类型名或函数名等作为标识,以免影响程序的正常运行
- 标识符对英文字母大小写是区分的
🚀 保留字
查看保留字
import keyword |
输出
- Python中的保留字:[‘False’, ‘None’, ‘True’, ‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘nonlocal’, ‘not’, ‘or’, ‘pass’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]。
🚀 注释
增加程序的可读性,也为以后程序修改提供帮助
Python中的注释有单行注释、多行注释和批量注释。
单行注释:将要注释的一行代码以#开头。
多行注释:将要注释的多行代码以#开头,或将要注释的多行代码放在成对'''(3个单引号)和"""(3个双引号)之间
# 这是一个注释 |
🚀 代码缩进
python采用严格的“缩进”来表明程序的格式框架,用来表示代码直接的包含和层次关系
- 和其它程序设计语言(如 Java、C 语言)采用大括号“{}”分隔代码块不同,Python 采用代码缩进和冒号( : )来区分代码块之间的层次
- 在 Python 中,对于类定义、函数定义、流程控制语句、异常处理语句等,行尾的冒号和下一行的缩进,表示下一个代码块的开始,而缩进的结束则表示此代码块的结束
score = 88 |
🚀 多行书写一条语句
Python通常是一行书写一条语句。如果语句很长,也可以多行书写一条语句。可以使用反斜杠
\来实现
\
a=5 |
多行书写[]中的语句
list1 = [1, 2, |
🚀 一行书写多条语句
Python可以在一行中书写多条语句,语句之间使用分号
;隔开
a = 1.2; b = 2.3; c = a + b |
🚀 空行
- 编码格式声明、模块导入、常量和全局变量声明、顶级定义和执行代码之间空两行
- 顶级定义之间空两行,方法定义之间空一行
- 在函数或方法内部,可以在必要的地方空一行以增强节奏感,但应避免连续空行
使用必要的空行可以增加代码的可读性,通常在顶级定义(如函数或类的定义)之间空两行,而方法定义之间空一行,另外在用于分隔某些功能的位置也可以空一行
import math |
🚀 语句块
缩进相同的一组语句构成一个语句块,又称为语句组。如
if、while、def和class这样的复合语句
if True: |
🚀 模块及模块对象导入
Python默认安装仅包含基本的核心模块,启动时只加载了基本模块。在Python中使用
import导入模块或模块对象,有如下几种方式:
- 导入整个模块。格式为:
import 模块名 [as 别名]- 导入模块的单个对象。格式为:
from 模块名 import 对象 [as 别名]- 导入模块的多个对象。格式为:
from 模块名 import对象1,对象2, …- 导入模块的全部对象。格式为:
from 模块名 import *
import 模块名
import math |
from模块名 import对象 [as 别名]
import math as m |
from模块名 import对象1,对象2, …
from math import fabs,sqrt |
每个 import 语句只导入一个模块,尽量避免一次导入多个模块
#推荐 |
🚀 字符编码及转换
在计算机中常见的几种字符编码如下:
ASCII:占1个字节8位,采用二进制进行编码。例如,’A’的ASCII为65,’0’的ASCII为48
Unicode:又称为万国码或统一码,占2个字节16位,包含了世界上大多数国家的字符编码。例如,汉字’严’的Unicode是十六进制数4E25
UTF-8:变长编码方式,使用1~4个字节表示一个符号,根据不同的符号而改变字节长度。例如,汉字’严’的UTF-8是十六进制数E4B8A5
GBK:专门用来解决中文编码,是在国家标准GB2312基础上扩容后兼容GB2312的标准,中英文都是双字节的
在Python 2.X中默认的字符编码为ASCII。如果要处理中文字符,则需要在源文件的开头添加”#-coding=UTF-8-“
Python 3.X默认的字符编码是Unicode编码,支持大多数不同国家的语言。因此,Python 3.X程序可以直接使用包括汉字的各种字符
如果需要对字符进行不同编码格式的转换,可以使用str.encode()函数和str.decode()函数
str_unicode = "工业" #Unicode格式. |
输出
- str_unicode: <class ‘str’> , 工业
str_utf8: <class ‘bytes’> , b’\xe5\xb7\xa5\xe4\xb8\x9a’
str_unicode: <class ‘str’> , 工业
str_gbk: <class ‘bytes’> , b’\xb9\xa4\xd2\xb5’
str_unicode: <class ‘str’> , 工业
1.5 输入、输出函数
🚀 input()函数
Python提供
input()函数由标准输入读入一行文本,默认标准输入是键盘,其一般格式为:
变量 = input(['提示字符串'])用户按
Enter完成输入,在按Enter之前,所有内容作为输入字符串赋给变量
姓名 = input("请输入您的姓名: ") |
输出
- 请输入您的姓名: 张时贰
请输入您的性别和职业: 男 学生
您的姓名: 张时贰, 性别: 男, 职业: 学生.
op1 = int(input("请输入一个数: ")) |
输出
- 请输入一个数: 1
请输入一个数: 2
1 + 2 = 3.
🚀 print()函数
🚁 使用print()函数输出
使用print()函数输出的一般格式为:
print(obj1,obj2,...,sep=' ',end='\n',file=sys.stdout)obj1, obj2, …:输出对象
sep:分隔符,即参数obj1,obj2,…之间的分隔符,默认没有间隔
end:终止符,默认为
'\n'file:输出位置,即输出到文件还是命令行,默认为
sys.stdout,即命令行(终端)
print()函数默认会换行
print(1) #数值类型可以直接输出 |
输出
- 1
Hello World
1 Hello World
ZhangShier
Zhang Shier
www.csdn.net
ZhangShier ZhangShier
🚁 使用print()函数格式化输出
在C语言中,我们可以使用
printf("%-.4f",a)之类的形式,实现数据的的格式化输出。和C语言的区别在于,Python中格式控制符和转换说明符用%分隔,C语言中用逗号
print()函数格式化输出的一般格式为:print("格式化字符串"%(变量、常量或表达式))其中,格式化字符串中包含一个或多个格式指定格式参数,与后面括号中的变量、常量或表达式在个数和类型上一一对应。当有多个变量、常量或表达式时,中间用逗号隔开
a = 100 |
输出
- a = 100 (十进制).
a = 144 (八进制).
a = 64 (十六进制).
f = 123.46
f = 1.234600e+02
字符串: Tiger
字符: T
她是航天员 刘洋,飞天年龄 34 岁.
🚁 格式字符归纳
| 格式字符 | 说明 | 格式字符 | 说明 |
|---|---|---|---|
| %s | 字符串采用str()的显示 | %x | 十六进制整数 |
| %r | 字符串(repr())的显示 | %e | 指数(基底写e) |
| %c | 单个字符 | %E | 指数(基底写E) |
| %b | 二进制整数 | %f,%F | 浮点数 |
| %d | 十进制整数 | %g | 指数(e)或浮点数(根据显示长度) |
| %i | 十进制整数 | %G | 指数(E)或浮点数(根据显示长度) |
| %o | 八进制整数 | %% | 字符% |
2 基础
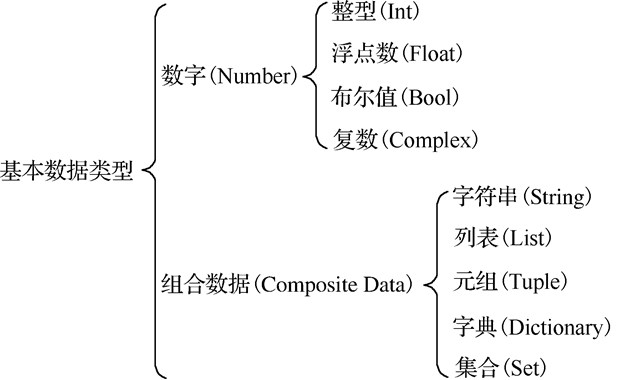
2.1 数据类型
Python支持丰富的数据类型,其中标准的数据类型6个
- Number(数字),如1、-2、3.0、5+6j、True
- String(字符串),如’Internet’、”长城”
- List(列表),如[1, 2, 3]、[“Spring”, “Summer”, “Autumn”, “Winter”]
- Tuple(元组),如(1, 3, 5)、(“大学”, “中学”, “小学”)
- Dictionary(字典),如{1: “优秀”, 2: “良好”, 3: “合格”, 4: “不合格”}
- Set(集合),如{“成功”, “失败”}
2.2 数字类型
Python中的基本数据类型可以分为两类:数字和组合数据数字包括整数、浮点数、布尔值和复数,组合数据包括字符串、列表、元组、字典、集合
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建
🚀 2.2.1 整型
整型(Int),又称为整数,包括正整数、负整数和零, 在Python中,整型不限制大小,没有Python 2.X中的长整型(Long),整数可以是二进制、八进制、十进制和十六进制整数
- 十进制整数,使用0~9共10个数字表示,如3、-4、0等
- 二进制整数,只需要用2个数字(0和1)就可以表示,以0B或0b开头,如0B1011(相当于十进制的11)、-0b101(相当于十进制的-5)
- 八进制整数,需要用8个数字(0~7)表示,以0o或0O 开头,如0o56(相当于十进制的46)、-0O145(相当于十进制的-101)
- 十六进制整数,需要用16个数字(0~F)表示,以0x 或0X开头,如0xAF(相当于十进制的175)、-0X123(相当于十进制的-291)
不同进制的数可以通过以下Python内置函数相互转化
- bin()函数:将其他进制的数转换成二进制数
- int()函数:将其他进制的数转换成十进制数
- oct()函数:将其他进制的数转换成八进制数
- hex()函数:将其他进制的数转换成十六进制数
# 不同进制的整数相互转化 |
🚀 2.2.2 浮点型
浮点(Float)类型的数包括整数部分和小数部分,可以写成普通的十进制形式,也可以用科学计数法表示(带有指数的浮点数),十进制表示的浮点数,如0.62、-3.87、0.0等
科学计数法表示的浮点数,如32.6e18(相当于3.26×1019),-9.268E-3(相当于-0.009268)
在Python中,提供大约17位的精度和范围从-308到308的指数,不支持32位的单精度浮点数
f = 32.6e18 |
输出
f = 3.26e+19
f = 3.260000e+19
f = 32600000000000000000.000000
# 浮点数运算 |
输出
a + b = 0.30000000000000004
(a + b) != 0.3
🚀 2.2.3 复数类型
复数(Complex):由实数部分和虚数部分构成,可以用a + bj或a + bJ或complex(a, b)表示,如12.6 + 5j,-7.4-8.3J。复数z可以用
z.real来获得实部,用z.imag来获得虚部
# 复数及其运算 |
输出
- c1 + c2 = (5.8+66.1j)
🚀 2.2.4 布尔类型
布尔类型(Bool)的常量包括
True和False,分别表示真和假。非0数字、非空字符串、非空列表、非空元组、非空字典、非空集合等在进行条件判断时均视为真(True);反之视为假(False)
兴趣 = ["武术","艺术","音乐","体育"] |
输出
- 列表’兴趣’不为空!
布尔类型的常量(True和False)如果出现在算术运算中,True 被当作 1,False 被当作 0
print(True + 2) //3 |
🚀 2.2.5 数字类型转换
Python中的几个内置函数可以进行数字类型之间数据的转换
- int(x)函数:将x转换为一个整数
- float(x)函数:将x转换为一个浮点数
- complex(x)或complex(x, y)函数:其中,complex(x)将x转换为一个复数,实数部分为x,虚数部分为0
- bool(x)函数:将非布尔类型数x转换为一个布尔类型常量
# 数字类型转换 |
🚀 2.2.6 分数和高精度实数
# 分数运算和高精度实数运算 |
🚀 2.2.7 常用数学函数
Python中的数学函数有两种使用方式
- Python中的常用内置数学函数
- Math中的常用数学函数
import math |
输出
- x_ = 3.186666666666667
s = 0.1236482466066093
2.3 字符串类型
字符串是Python中最常用的数据类型之一,是一个有序的字符集合,用来存储和表现基于文本的信息
Python字符串需要使用成对的单引号
'或双引号"括起来,如”Python”、”中国制造”等。在Python中,单引号(‘)字符串和双引号(“)字符串是等效的Python还允许使用三引号
''''''或"'创建跨多行的字符串,这种字符串中可以包含换行符、制表符及其他特殊字符提示:在Python中,不支持字符类型,单个字符也是字符串
Python为字符串中的每个字符分配一个数字来指代这个元素的位置,即索引,第一个元素的索引是0,第二个元素的索引是1,以此类推,同时,字符串还支持反向索引,字符串中最后一个字符的索引是-1,倒数第二个字符的索引是-2,以此类推

- Unicode字符串:不以u/U、r/R、b/B开头的字符串,或以u或U开头的字符串
- 非转义的原始字符串:以r或R开头的字符串
- bytes字节串:以b或B开头的字符串
除可以使用encode()函数和decode()函数在Unicode字符串与bytes字节串之间转换外,也可以使用str()函数和bytes()函数在这二者之间进行转换
# 不同类型字符串及其转换 |
🚀 2.3.1 字符串及创建
# 使用赋值运算符(=)创建字符串 |
输出
str1: prognosticate
str2: evaluation
str3: 这是三引号字符串
可以包含转义字符
# 使用str()或repr()函数创建字符串 |
🚀 2.3.2 字符串访问
str = "sophiscated" |
从左往右读,
:即开区间
🚀 2.3.3 字符串运算
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | ‘H’ in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | ‘M’ not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print( r'\n' ) print( R'\n' ) |
# 字符串运算 |
# 使用Operator中的函数比较字符串大小 |
输出
‘superman’ < ‘monster’: False
‘superman’ <= ‘monster’: False
‘superman’ == ‘monster’: False
‘superman’ != ‘monster’: True
‘superman’ > ‘monster’: True
‘superman’ >= ‘monster’: True
🚀 2.3.4 字符串函数
🚁 字符串查找函数
str.find(str, beg=0, end=len(string)):find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1str.rfind(str, beg=0, end=len(string)):从右边开始查找str.index(str, beg=0, end=len(string)):查找字符串str中是否包含子字符串str,如果包含则返回子字符串str在str中第一次出现的索引值,否则出错str.startswith(substr, beg=0,end=len(string)):检查字符串str是否以指定子字符串substr开头str.endswith(subStr):检查字符串str是否以指定子字符串subStr结束
str = "时间是一切财富中最宝贵的财富" |
🚁 字符串替换函数
str.replace(oldStr,newStr[,max])
str = "贝多芬是世界闻名的航海家." |
🚁 字符串拆分函数
str.split(sep="",num),通过指定分隔符对字符串进行切片,分割为 num+1 个子字符串
str = "Every cloud has a silver lining." |
🚁 ord()和chr()
ord()函数和chr()函数是一对与编码相关而功能相反的函数
- ord(c):返回单个字符的Unicode编码
- chr(u):返回Unicode编码对应的字符
两个字符串之间的比较一般遵循如下规则:
- 如果都是西文字符串,则按照字符串每个字符的ASCII编码逐个进行比较
- 如果都是中文字符串,则按照汉字的Unicode编码逐个进行比较
- 如果分别是汉字字符串和英文字符串,则统一按照它们的Unicode编码逐个进行比较,汉字字符串大于英文字符串
print("ord(c) =",ord("c")) # ord(c) = 99 |
🚁 字符串格式化函数
format()一般格式为:'格式化字符串'.format(参数列表),格式化字符串:包括参数序号和格式控制信息的字符串
参数序号和格式控制信息包含在{}中
格式化符号和print()函数中的类似
- *:自定义宽度或小数点精度
- +:在正数前面显示加号(+)
- -:左对齐
- m.n.:显示最小总宽度为m,小数点后的位数为n
#根据位置格式化 |
🚁 例题
phone = input("请输入电话号码: ") |
🚀 2.3.4 常用转义字符
| 转义字符 | 描述 | 转义字符 | 描述 |
|---|---|---|---|
| \(在行尾时) | 续行符 | \n | 换行 |
| \\ | 反斜杠符号 | \v | 纵向制表符 |
| \‘ | 单引号 | \t | 横向制表符 |
| \“ | 双引号 | \r | 回车,将 \r 后面的内容移到字符串开头, 并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成 |
| \a | 响铃 | \f | 换页 |
| \b | 退格(Backspace) | \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行 |
| \e | \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | |
| \000 | 空 | \other | 其它的字符以普通格式输出 |
print("很多观众喜欢\"汉武大帝\"这部电视剧.") |
2.4 常量和变量
2.4.1 常量
常量一般指不需要改变也不能改变的常数或常量,如一个数字3、一个字符串”火星”、一个元组(1, 3, 5)等
Python中没有专门定义常量的方式,通常使用大写变量名表示。但是,这仅仅是一种提示和约定俗成,其本质还是变量
PI = 3.14 #定义一个常量. |
2.4.2 变量
🚀 变量概述
- 与常量相反,变量的值是可以变化的
- 在Python中,不仅变量的值可以变,其类型也可以变
- 在使用变量的时候,不需要提前声明,只需要给这个变量赋值即可。当给一个变量赋值时即创建对应类型的变量
- 当用变量的时候,必须给这个变量赋值。如果只声明一个变量而没有赋值,则Python认为这个变量没有定义
m = 120 |
只声明一个变量而没有赋值
x = 50 |
🚀 变量命名
- Python中变量的命名遵循标识符的规定,可以使用大小写英文字母、汉字、下画线、数字
- 变量名必须以英文字母、汉字或下画线开头,不能使用空格或标点符号(如括号、引号、逗号等)
#合法变量 |
🚀 变量赋值
在使用Python中的变量前都必须给变量赋值,变量赋值后才能在内存中被创建。Python使用
赋值运算符(=)给变量赋值,其一般格式为:
变量1,变量2,变量3,… = 表达式1,表达式2,表达式3,…如果多个变量的值相同,也可以使用如下格式:
变量1 = 变量2 = … = 变量n = 表达式
counter = 68 |
🚀 例题
交换两个变量的值
a = 50; b = 60 |
给不同变量赋相同的数值,利用
id获取内存位置,每一次运行指向都不同
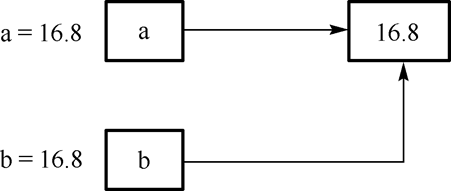
a = 16.8 |
给不同变量赋相同的列表,每一次运行指向都不同
x = ["王羲之","顾恺之","阎立本","颜真卿"] |
变量复制

a = 100 |
2.5 运算符和表达式
2.5.1 常用运算符
🚀 算术运算符和算术运算表达式
算术运算符用于对算术运算对象进行算术运算,由算术运算符与算术运算对象组成的式子称为算术运算表达式
a=10,b=2
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 31 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -11 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 210 |
| / | 除 - x 除以 y | b / a 输出结果 2.1 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 1 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的21次方 |
| // | 取整除 - 向下取接近商的整数 | 9//2 4 |
#求自然数268的逆序数并输出 |
🚀 关系运算符和关系运算表达式
- 关系运算符用来比较两个对象之间的关系,对象可以是数或字符串等常量、变量或表达式
- 由关系运算符与比较对象组成的表达式称为关系运算表达式
- 关系表达式的结果为真返回True,否则返回False
a=1,b=2
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写 | (a < b) 返回 True |
| >= | 大于等于 - 返回x是否大于等于y | (a >= b) 返回 False |
| <= | 小于等于 - 返回x是否小于等于y | (a <= b) 返回 True |
🚀 赋值运算符和赋值运算表达式
- 赋值运算符用来将表达式的结果赋给变量
- 由赋值运算符与赋值运算对象组成的式子称为赋值运算表达式
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,可在表达式内部为变量赋值 | a = 1 if a > 0: print("1>0")等同于if a:=1 > 0: print("1>0") |
a = b = c = 100 |
🚀 逻辑运算符和逻辑运算表达式
a=10,b=20
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与” - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值。 | (a and b) 返回 20 |
| or | x or y | 布尔”或” - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10 |
| not | not x | 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
True and True # True |
🚀 位运算符和位运算表达式
位运算符用来把两个运算对象按照二进制进行位运算,由位运算符与位运算对象组成的式子称为位运算表达式
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由”<<”右边的数指定移动的位数,高位丢弃,低位补0 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把”>>”左边的运算数的各二进位全部右移若干位,”>>”右边的数指定移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
使用“^”运算符对字符加密和解密。
key = input("请输入加密密钥: ") |
🚀 成员运算符和成员运算表达式
成员运算符用来判断两个对象之间的关系。由成员运算符与成员运算对象组成的式子称为成员运算表达式
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True |
成员运算符的使用
元曲四大家 = ["关汉卿"," 白朴"," 郑光祖","马致远"] |
🚀 身份运算符和身份运算表达式
身份运算符用来比较两个对象之间的存储单元, 由身份运算符与身份运算对象组成的式子称为身份运算表达式
| 运算符 | 描述 | 实例(id指内存地址) |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(x) != id(y) 。如果引用的不是同一个对象则返回结果 True,否则返回 False |
注意区分
a == b:比较对象a和对象b的值是否相等a is b:比较对象a和对象b是否有相同的引用,即id是否相等,相当于java中equaloperator.eq(a, b)函数:与a == b同理
比较两个整型变量
import operator |
比较两个列表对象
import operator |
2.5.2 运算符优先级
从最高到最低优先级的所有运算符
| 运算符 | 描述 |
|---|---|
** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
* / % // | 乘,除,求余数和取整除 |
| + - | 加法减法 |
>> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
^ ` | ` |
<= < > >= | 比较运算符 |
| == != | 等于运算符 |
= %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
使用运算符计算表达式
a = 10; b = 20; c = 30; d = 40 |
2.5.3 补充说明
Python中的一些运算符不仅可用于数字等运算,还可以用于对字符串、列表和元组等组合对象的运算
Python支持++i、–i运算符,但含义和其他语言中的不同
Python不支持**i++、i–**运算符
++和--
i = 2 |
2.6 特殊内置函数
2.6.1 内置函数简介
- 内置函数(Built-In Functions,BIF)是Python的内置对象类型之一,封装在标准库模块
_ _builtins_ _中- 可以直接在程序中使用,如
input()函数、print()函数、abs()函数等- Python中的内置函数使用C语言进行了大量优化,运行速度快,推荐优先使用
使用help()函数查看内置函数用法。
help("函数名")
help("pow") |
2.6.2 特殊内置函数
🚀 range()函数
range()函数返回一个整数序列的迭代对象,其一般格式为:
range([start,]stop[,step])
其中,
start为计数初始值,默认从0开始。
stop为计数终值,但不包括 stop。
step为步长,默认值为1。当start比stop大时,step为负整数。
list(range(10)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] |
🚀 type()和isinstance()函数
type(object):接收一个对象object作为参数,返回这个对象的类型isinstance(object, class):判断接收的对象object是否是给定类型class的对象:如果是,则返回True;否则返回False
使用type()函数和isinstance()函数判断对象类型
print("'innovate'的类型是:",type("innovate")) # 'innovate'的类型是: <class 'str'> |
🚀 eval()函数
eval()函数用来执行一个字符串表达式,并返回表达式的值,其一般格式为:eval(expression[,globals[,locals]])
其中,expression为表达式,globals为变量作用域,可选,必须是一个字典对象,locals为变量作用域,可选,可以是任何映射(map)对象
c=eval('2 + 3') |
🚀 map()函数
map()函数把函数依次映射到序列或迭代器对象的每个元素上,并返回一个可迭代的map对象作为结果,其一般格式为:map(function,iterable,…), 其中,function为被调用函数,iterable为一个或多个序列
def cube(x): |
🚀 filter()函数
filter()函数用于过滤掉不符合条件的元素,返回一个迭代器对象,其一般格式为:filter(function,iterable)
def IsEvenFunc(n): |
🚀 zip()函数
zip()函数接收任意多个可迭代对象作为参数,将对象中对应的元素打包成一个元组,然后返回一个可迭代的zip对象,其一般格式为:zip([iterable,...]),iterable为一个或多个迭代器。
a=list(zip(["泰山","黄山","庐山","华山"],["山东","安徽","江西","陕西"])) |
*zip[iterable]表示将元素解压开
🚀 枚举函数enumerate()
枚举函数
enumerate()用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,其一般格式为:enumerate(sequence,[start = 0]),sequence:一个序列、迭代器或其他支持的迭代对象。start:下标起始位置,可选
weeks = ['Sunday','Monday','Tuesday','Wednesday','Thursday','Friday','Saturday'] |
2.7 典型案例
🚀 2.7.1 计算复杂算术运算表达式的值
计算算术运算表达式
import math |
🚀 2.7.2 求几何面、几何7的(表)面积或体积
计算圆锥体的表面积和体积
import math |
🚀 2.7.3 解一元二次方程
求方程2x^2^+3x+1=0的根
import math |
🚀 2.7.4 验证码验
编程实现验证码验证
import random |
3 程序设计结构
3.1 概述
python与C++,java一样,按照设计方法的不同,计算机程序设计也有面向对象程序设计和面向过程程序设计
首先样子先来学习
if...else...,while…结构化程序有三种基本结构:顺序结构、选择结构和循环结构
- 顺序结构:程序由上到下依次执行每条语句
- 选择结构:程序判断某个条件是否成立,决定执行哪部分代码
- 循环结构:程序判断某个条件是否成立,决定是否重复执行某部分代码
3.2 顺序结构
在程序的顺序结构中,依次执行程序代码的各条语句

a = 5 |
3.3 选择结构
🚀 3.3.1 单分支结构
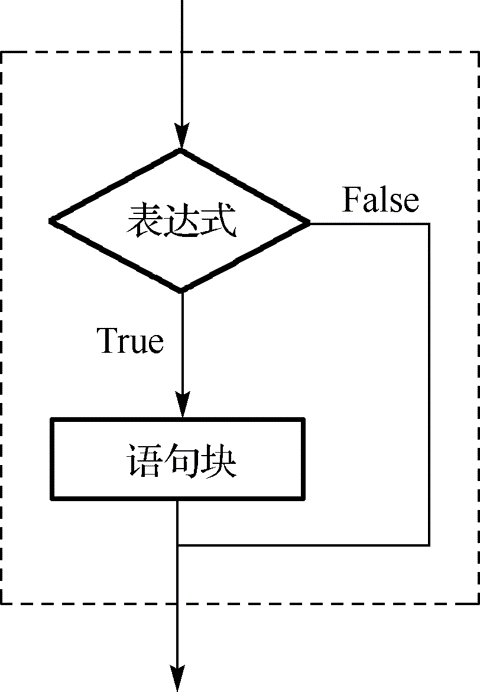
单分支结构可用if单分支语句实现,其一般格式为:
语句块
语句的执行过程是:如果表达式的值为True,则执行语句中的语句块;否则,直接执行if语句的后续语句
- if语句中的语句块可以包含单个语句或多个语句
- 如果语句块中只有一条语句,可以写在同一行中
判断从键盘输入整数的奇偶性并输出结果
n = int(input("请输入一个整数: ")) |
从键盘输入两个整数,然后按照从大到小的顺序输出这两个数
x = int(input("请输入一个整数: ")) |
🚀 3.3.2 二分支结构
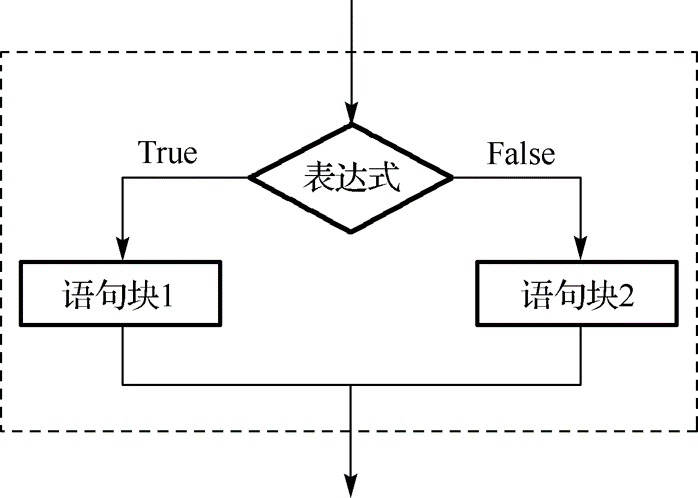
二分支结构可用if二分支语句实现,其一般格式为:
语句块1
else:
语句块2语句执行过程是:如果表达式的值为True时,则执行语句块1;否则,执行语句块2
求两个数中较大的数并输出
a = 5 |
根据输入的x,求分段函数y的值
$$
\begin{cases}
e^{x-1} &x<2\
log_2(x^2-1)&x≥2\
\end{cases}
$$
from math import exp,log |
🚀 3.3.3 多分支结构
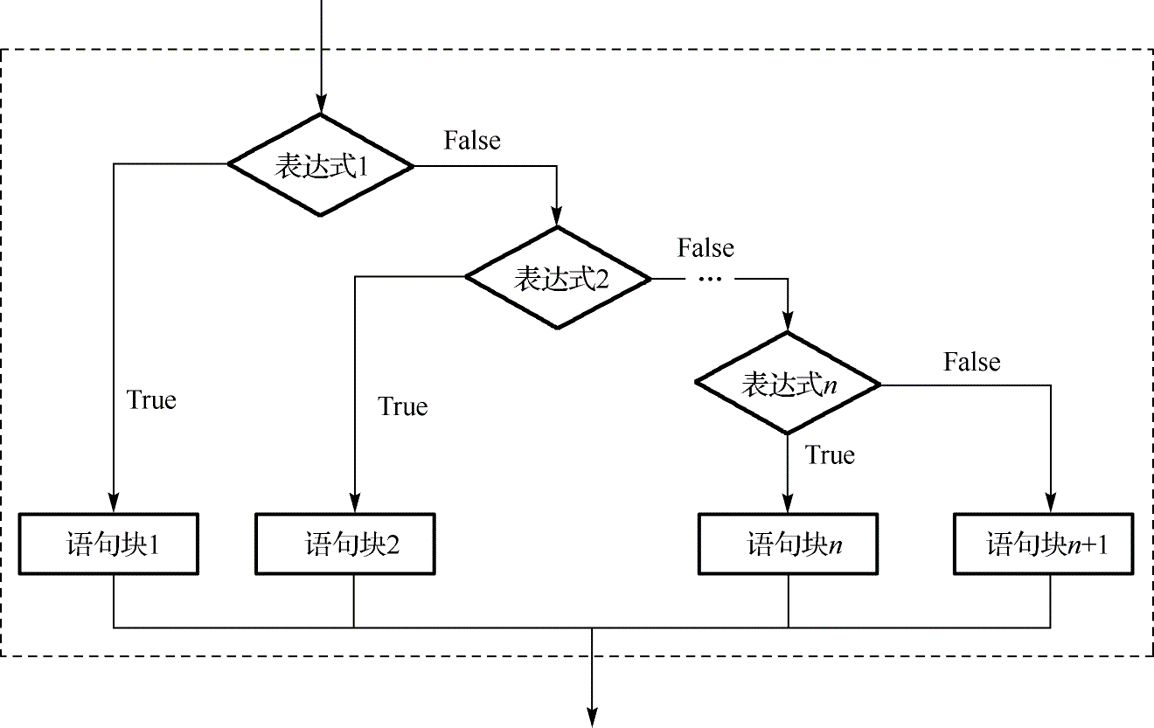
多分支结构可用
if多分支语句实现,其一般格式为(注意python中的elseif没有空格):
语句块1
elif表达式2:
语句块2
…
[else:
语句块n+1]
使用if多分支语句判别键盘输入成绩等级并输出
score = int(input("请输入成绩: ")) |
使用if多分支语句实现简单的算术运算
x, op, y = input("请输入操作数和操作符: ").split() |
🚀 3.3.4 条件运算
条件运算相当于一个二分支结构语句的功能,包含三个表达式,其一般格式为:
条件运算的执行过程是:如果if后面的表达式值为True,则以表达式1的值为条件运算的结果;否则,以表达式2的值为条件运算的结果
判断从键盘输入的学生成绩是否合格
score = int(input("请输入学生成绩: ")) |
🚀 3.3.5 选择结构嵌套
求三个数中最大的数并输出
a = 3; |
3.4 循环结构
🚀 3.4.1 while语句
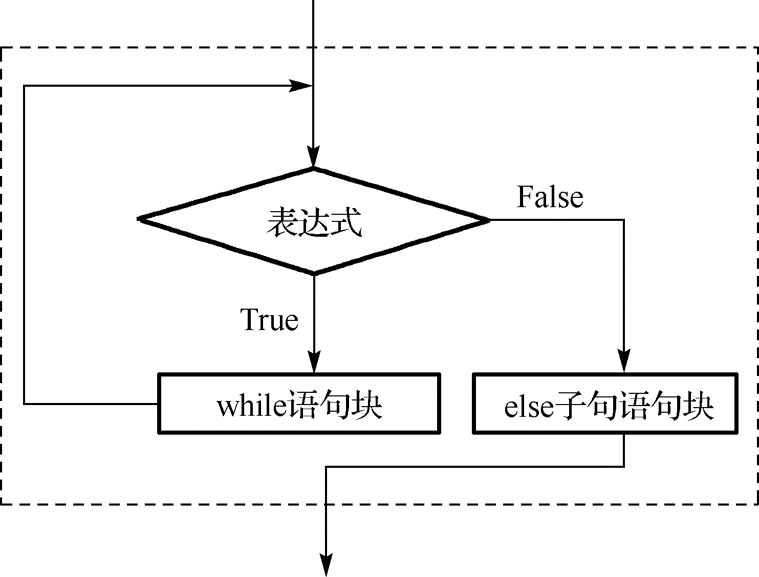
while 语句用于循环执行一段程序,一般来说使用在循环次数不确定!while语句的一般格式为:
语句块
[else:
else子句语句块]
使用while语句计算1~100的和
n = 100 #终止值. |
使用while-else语句求$\sum_{10}^{i=1} i!$
mul = 1; i = 1; sum = 0 |
🚁 while语句块中的input()函数
通过键盘动态录入学生的英语成绩,输入-1退出录入成绩,并计算录入学生英语成绩的人数、总分和平均分
total = 0; |
完善,因为分数不能是负数或者无限大,在逻辑上是不对的
total = 0; |
🚀 3.4.2 for语句
在Python中,for语句更适合循环访问系列或迭代对象(如字符串、列表、元组、字典等)中的元素,常用在循环次数确定的循环体种,其一般格式为
语句块
[else:
else子句语句块]
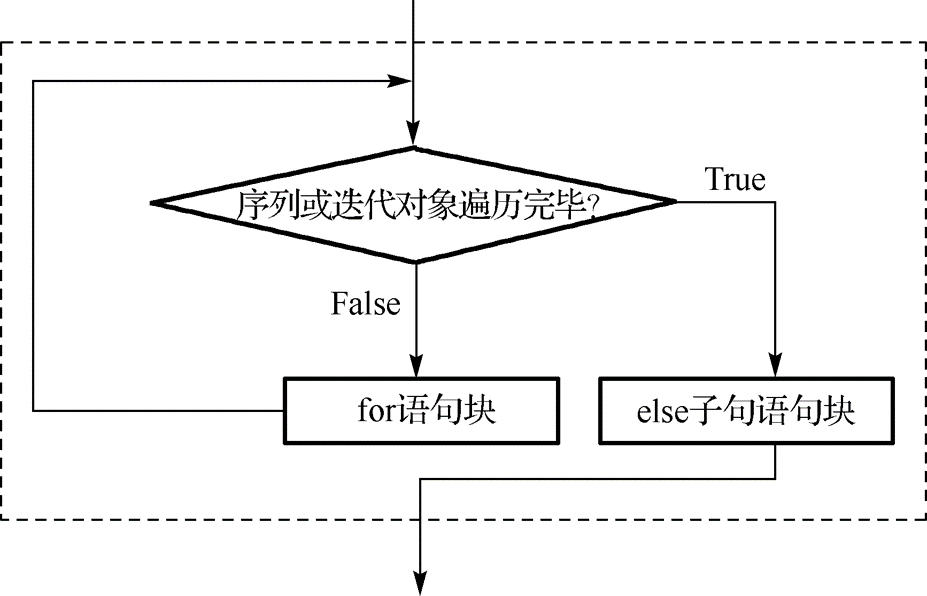
使用for语句遍历列表中的元素
for letter in 'Python': |
使用for-else语句遍历元组中的元素并在结束后给出提示信息
mathematicians = ('阿基米德','牛顿','高斯','庞加莱') |
🚁 for语句中的range()函数
在for语句中使用range()函数控制循环次数(range是0-2)
universities = ["哈佛大学","斯坦福大学","剑桥大学","麻省理工学院","加州大学-伯 |
求1~20范围内能被3整除的所有数的和
# 通过设置range()函数的步长为3实现。 |
# 通过判断该数除以3的余数是否为0实现。 |
🚀 3.4.3 break语句、continue语句和pass语句
- break语句:退出循环
- continue语句:跳过该次循环
- pass:空语句(不做任何处理)
通过上述3种语句,可以控制循环的执行和保持程序结构的完整
输出斐波那契数列前10项,斐波那契公式:F(i)=F(i-1)+F(i-2),F(1)=F(2)=1
n1 = 1 #第1项 |
求1~10范围内所有偶数的和
i = 1; n = 10; sum = 0 |
验证客户的股票抽签号是否中签。中签的股票抽签号以88开头且8位
stockNum = input("请输入您的股票抽签号:") |
🚀 3.4.4 循环结构嵌套
输出元素为”*”、5行5列的左下角直角三角形
for i in range(1,6): #外循环次数: 5. |
输出对角线元素为1的4行4列矩阵
for i in range(1,5): #行数为4 |
3.5 典型案例一
🚀 计算部分级数和
$$1+\frac{1}{1!}+\frac{1}{2!}+\frac{1}{3!}+…+\frac{1}{n!}=1+\sum_{1 }^{\infty }\frac{1}{i!}$$,最后一项精度为0.00001
while实现
i = 1; sum = 1; n = 1 |
for实现
sum = 1; n = 1 |
🚀 使用选择结构计算员工工资
某公司员工的工资计算方法为:
- 月工时数在120~180内,每小时按80元计算
- 月工时数超过180,超过部分加发20%
- 月工时数低于120,扣发10%
ygss = float(input("请输入月工时数: ")) |
🚀 用递推法求解实际问题
猴子吃桃问题。一只猴子一天摘了若干个桃子。
第1天,猴子吃了一半多一个
第2天,猴子吃了剩下的一半多1个
以后每天吃了剩下的一半多1个
在第5天早上要吃时发现只剩下1个了
问:猴子最初摘了多少个桃子?
分析:这是一个迭代问题。先由最后1天剩下的桃子数推出倒数第2天的桃子数,再从倒数第2天推出倒数第3天的桃子数……
$$
\begin{cases}
x_{n}=\frac{1}{2}x_{n-1}-1 \
x_{n-1}=(x_{n}+1)\times 2 \
\end{cases}
$$
x = 1 #最后一天的桃子数. |
🚀 “试凑法”解方程
古代数学中的百元百鸡问题。假定公鸡2元/只,母鸡3元/只,小鸡0.5元/只。现有100元,要求买100只鸡,编程列出所有可能的购鸡方案
分析:根据题意,设公鸡、母鸡和小鸡各为x只、y只和z只,列出方程组为:
$$
\begin{cases}
x + y + z=100 \
2x + 3y + 0.5z=100 \
\end{cases}
$$
for x in range(51): #x为公鸡数,100元最多买50只. |
🚀 计算机猜数
利用计算机程序做猜数字游戏:计算机程序产生一个[1, 100]范 围的随机整数key;用户输入猜数x
计算机程序根据下列3种猜数情况做出提示:
- x > key:猜大了
- x < key:猜小了
- x == key:猜对了
在程序执行时,如果用户5次还没有猜中就结束游戏程序,并公布正确答案。
分析:计算机猜数是计算机二分查找算法的一种应用。基本方法是折半处理,即将要查找的范围每次缩小一半
import random |
🚀 模拟自动饮料机
编程实现模拟自动饮料机功能:
- 当输入数字0时,模拟自动饮料机停止运行
- 当输入数字1~5时,模拟自动饮料机给出对应的饮料
- 当输入其他数字时,模拟自动饮料机给出非法操作信息,并提示用户重新输入
分析:
正常情况下,模拟自动饮料机一直运行,输入不同的数字,对应不同的饮料
只有当出现故障或需要添加饮料时才停止运行
可以采用在while语句中嵌套if-elif-else多分支语句实现程序功能
投币 = int(input("请投币: ")) |
3.6 典型案例二
🚀 判断一个数是否是素数并输出
什么是素数?除了1和它本身能被其它数整除。1不属于素数,所以咱们就从2开始遍历
num=int(input("请输入一个数")) |
优化一下第五行,如果把这个数开根号,num=a^2^,如果比a小的数都没被整除那他就是素数,就不需要考虑比a大的数了
num=int(input("请输入一个数")) |
🚀 输入两个正整数,找出最大公约数并输出
找最大公约数有很多算法
穷举法:num1>num2。从num2开始遍历,与num1和num2做除法每次-1,直到num1和num2都可以整除
更相减损法:
任意给定两个正整数;判断它们是否都是偶数。若是,则用2约简;若不是则执行第二步
以较大的数减较小的数,接着把所得的差与较小的数比较,并以大数减小数。继续这个操作,直到所得的减数和差相等为止
则第一步中约掉的若干个2的积与第二步中等数的乘积就是所求的最大公约数
辗转相除法:用较小数除较大数,再用出现的余数(第一余数)去除除数,如此反复,直到最后余数是0为止
辗转相除法程序运行时间最短,所以这里就以辗转相除法为例子,另外两种也很容易实现
graph TD;
id1["num1%num2==0"]-->|Yes| 最大公约数是num2;
id1["num1%num2==0"]-->|No| id2["num3=num1%num2"];
id2-->id3["num1=num2,num2=num3"]
id3-->id1
num1=int(input("请输入第一个数")) |
🚀 计算Π/4
计算出Π的近似值︰$\frac{Π}{4}$≈1-1/3+1/5-1/7+1/9-……(计算到最后一项的值小于10-6为止)
num=1 |
🚀 打印九九乘法表
1 * 1 = 1 |
首先看下乘法表,有什么规律?公式
j*i,利用公式反推原理,公式中的j就可以代表列数,公式里的i可以代表行数。所以用两个for嵌套一下
for i in range(1,10): |
🚀 水仙花数
水仙花数为一个三位数,并且每一位上的数字的立方和等于该数。求所有三位数的水仙花数
for i in range(100,1000): |
🚀 完全数
找出100以内的完全数(比如6=1+2+3,6就是一个完全数,一个数刚好等于它的因子和)
for i in range(1,101): |
🚀 小结
这六个题,没什么太难的地方,主要就是考虑逻辑,学过其它语言的伙伴应该也见过这些例题,初学的小伙伴看不懂前两个题的优化也没关系,多敲多练!
4 组合数据
4.1 概述
Python中的组合数据类似于其他编程语言中的数组等,但类型更多、功能更强大。
在Python中,除字符串外,组合数据主要包括列表、元组、集合和字典等
| 数据类型 | 数据示例 |
|---|---|
| 列表 | {0,2,4,8,12} |
| 元组 | (‘Google’, ‘Runoob’, 1997, 2000) |
| 字典 | {‘name’: ‘runoob’, ‘likes’: 123, ‘url’: ‘www.csdn.net'} |
| 集合 | {‘Taobao’, ‘Facebook’, ‘Google’, ‘Youtube’} |
4.2 列表
4.2.1 列表创建
- 列表(List)是写在方括号
[]之间、用,隔开的元素集合- 列表中的元素可以是零个或多个,只有零个元素的列表称为空列表[]
- 列表中的元素可以相同,也可以不相同
- 列表中的元素可以类型相同
- 同字符串类似,列表支持元素的双向索引
🚀 语法
使用[]运算符创建列表,
列表名 = [元素1,元素2,元素3,…]
list1 = [] |
使用list()函数创建列表,
列表名 = list(sequence)
list1 = list() |
4.2.2 列表访问
访问列表
🚀 访问列表及元素
carList = ["奔驰","大众","福特","宝马","奥迪","雪佛兰"] #汽车品牌. |
🚀 列表切片
与
range()函数类似,[起点:终点:步长]
carList = ["奔驰","大众","福特","宝马","奥迪","雪佛兰"] |
🚀 遍历列表
carList = ["奔驰","大众","福特","宝马","奥迪","雪佛兰"] |
添加列表元素
列表创建后,可以使用列表函数或切片为列表添加新的元素
list.append(newItem)在列表末尾添加新元素list.insert(index, newItem)在索引为index的位置插入新元素list.extend(seq)在列表末尾添加迭代对象seq中的所有元素作为列表新元素list[len(list):] = newList使用切片在列表list末尾添加新元素(newList中的元素)
firsttier_city_list = ["北京","上海","广州","深圳"] |
修改列表元素
list[index]=newValue对指定索引index的列表元素进行修改。list[::] = newList对指定范围的列表元素进行修改
fruitList = ["苹果","梨子","桃子","火龙果"] |
删除列表元素
列表创建后,可以根据需要使用列表函数、del语句或切片删除指定元素或所有元素
del list[index]:删除索引为index的元素list.pop():删除列表末尾的元素list.pop(index):删除索引为index的元素list.remove(item):删除列表元素item(元素名)list.clear():删除列表中所有元素list[::] = []:对指定范围的列表元素进行删除
cityList = ["珠海","威海","信阳","惠州","厦门","金华","柳州","曲靖","九江","绵阳"] |
4.2.3 列表复制和删除
🚀 列表复制
list_copy = list.copy():列表浅复制list_copy = list:字典复制,list改变,list_copy也改变
planetList = ["水星","金星","地球","火星","木星","土星","天王星","海王星"] |
🚀 列表删除
当列表不再需要使用后,可以使用del语句删除列表,其一般格式为
del 列表名
capitalList = ["华盛顿","伦敦","巴黎","北京"] |
4.2.4 列表运算
+:将多个列表组合成一个新列表*:将整数n和列表相乘可以得到一个将原列表元素重复n次的新列表in:用于判断给定对象是否在列表中not in:用于判断给定对象是否不在列表中- 关系运算符:规则是从两个列表的第1个元素开始比较,如果比较有结果则结束;否则继续比较两个列表后面对应位置的元素
tang_list = ["韩愈","柳宗元"] |
4.2.5 列表统计
len(list):返回列表list中的元素个数max(list):返回列表list中元素的最大值min(list):返回列表list中元素的最小值sum(list):返回列表list中所有元素的和list.count(key):返回关键字key在列表中的出现次数
ktlsl_list = [1,1,2,5,14,42,132,429,1430,4862] |
4.2.6 列表查找与排序
🚀 列表元素查找
list.index(key)函数用于查找并返回关键字在列表中第1次出现的位置
animalList = ["elephant","tiger","lion","leopard","monkey"] |
🚀 列表元素排序
列表创建后,可以使用以下函数根据关键字对列表中的元素进行排序、倒序或临时排序
list.sort():对列表list中的元素按照一定的规则排序(或者list.sort( key=None, reverse=True/False),key指定元素排序)list.reverse():对列表list中的元素按照一定的规则反向排序sorted(list):对列表list 中的元素进行临时排序,返回副本
buildingList = ["金字塔","长城","埃菲尔铁塔","比萨斜塔","雅典卫城","古罗马竞技场"] |
4.3 元组
4.3.1 元组创建
元组(Tuple)是写在小括号
()之间、用,隔开的元素集合与列表不同,元组创建后,对其中的的元素不能修改
与列表相似,元组中的元素类型可以相同或不同,其中的元素可以重复或不重复,可以是简单或组合数据类型,元组的下标从0开始,支持双向索引
(1,1,2,3,5)中的元素为简单数字类型,有重复元素;((“语文”,122), ( “数学”,146),( “英语”,138))中的元素为元组类型,元素值各不相同
使用()运算符创建元组
元组名 = (元素1,元素2,元素3,…)
tuple1 = () #空元组 |
使用tuple()函数创建元组
元组名 = tuple(sequence)
tuple1=tuple(["莎士比亚","托尔斯泰","但丁","雨果","歌德"]) |
4.3.2 元组访问
🚀 访问元组及指定元素
通过
tuple[index]访问指定索引为index的元组元素
cityTuple = ("维也纳","苏黎世","奥克兰","慕尼黑","温哥华","杜塞尔多夫") |
🚀 元组切片
cityTuple = ("维也纳","苏黎世","奥克兰","慕尼黑","温哥华","杜塞尔多夫") |
🚀 遍历元组
cityTuple = ("维也纳","苏黎世","奥克兰","慕尼黑","温哥华","杜塞尔多夫") |
4.3.3 元组复制和删除
list_copy = list:复制del 列表名:删除
bat_tuple = ("百度","阿里巴巴","腾讯") |
4.3.4 元组运算
wanyue_tuple = ("柳永","晏殊","欧阳修","秦观","李清照") |
4.3.5 元组统计
len(list):返回列表list中的元素个数max(list):返回列表list中元素的最大值min(list):返回列表list中元素的最小值sum(list):返回列表list中所有元素的和list.count(key):返回关键字key在列表中的出现次数
pellTuple = (0,1,2,5,12,29,70,169,408,985) #佩尔数列 |
4.4 字典
4.4.1 字典创建
- 字典(Dictionary)是一种映射类型,用
{}标识,是一个无序的“键(key): 值(value)”对集合- 键(key)必须使用不可变类型,如字符串、数字等;值可以是简单数据或组合数据等多种不同类型
- 在同一个字典中,键(key)必须是唯一的,值可以是不唯一的
- 与列表通过索引(Index)访问和操作元素不同,字典当中的元素是通过键来访问和操作的
🚀 使用{}运算符创建字典
字典名 = {key1:value1,key2:value2,key3:value3,…}
dict1 = {} #空字典. |
🚀 使用dict()函数创建字典
dict1 = dict () # 空字典 |
4.4.2 字典访问
🚀 访问字典
通过字典名访问字典,通过“
dict[key]”或“dict.get(key)”访问指定元素
LSZ_dict = {"姓名":"李时珍","出生时间":1518,"籍贯":"湖北","职业":"医生"} |
遍历字典中所有元素
LSZ_dict = {"姓名":"李时珍","出生时间":1518,"籍贯":"湖北","职业":"医生"} |
🚀 添加字典元素
Libing_dict = {"姓名":"李冰","性别":"男","职业":"水利"} |
🚀 添加字典元素
dict[key] = value
dict1 = {"name":"Alice","sex":"female","age":21} |
🚀 添加字典元素
字典创建后,可以根据需要使用
字典函数或del语句删除指定元素或所有元素
del dict[key]:删除关键字为key的元素dict.pop(key):删除关键字为key的元素dict.popitem():随机删除字典中的元素dict.clear():删除字典中所有元素
influential_people_dict = {"牛顿":"物理学家","孔子":"儒家","亚里士多德":"哲学家","达尔文":"生物学家","欧几里得":"数学家","伽利略":"天文学家"} |
4.4.3 字典复制和删除
list_copy = list.copy():字典浅复制list_copy = list:字典复制,list改变,list_copy也改变del 列表名
chinese_figure_dict = {"张衡":"地质学家","张仲景":"医学家","祖冲之":"数学家"} |
4.5 集合
4.5.1 集合创建
- 集合(Set):在大括号
{}之间、用逗号分隔、无序且不重复的元素集合- 不可以为集合创建索引或执行切片(slice)操作
- 没有键(key)可用来获取集合中元素的值
- Python中可以使用
{}运算符或者set()函数创建集合
🚀 使用{}运算符创建集合
集合名 = {元素1,元素2,元素3,…}
set1 = {1,4,9,16,25} #元素为数字 |
集合名 = set(sequence)
set1 = set() #空集合 |
4.5.2 集合访问
🚀 访问集合元素
tourismSet = {"大峡谷","大堡礁","棕榈海滩","南岛","好望角","拉斯维加斯","悉尼港"} |
🚀 添加和修改集合元素
集合创建后,可以使用集合函数在集合中添加或修改元素
set.add(item):在集合中添加新元素item。set.update(sequence):在集合中添加或修改元素。
phoneSet = {"华为","苹果"} |
🚀 删除集合元素
set.remove(item):删除指定元素itemset.discard(item):删除指定元素itemset.pop():随机删除集合中的元素set.clear():清空集合中的所有元素
world_tournament_set = {"世界杯排球赛","世界乒乓球锦标赛","世界篮球锦标赛","世界足球锦标赛"} #世界球类大赛 |
4.5.3 集合复制和删除
list_copy = list.copy():列表浅复制list_copy = list:字典复制,list改变,list_copy也改变del 列表名
world_GDP_set = {"美国","中国","日本","德国","英国"} |
4.5.4 集合运算
set1.union(set2)或set1 | set2:并集运算set1.intersection(set2)或set1 & set2:交集运算set1. difference(set2)或set1 - set2:差集运算set1. issubset(set2)或set1 < set2:子集运算item in set或item not in set:成员运算
delicacySet1 = {"中国冰糖葫芦","墨西哥卷饼","英国炸鱼","美国热狗","土耳其烤肉","新加坡炒粿"} |
4.5.5 集合统计
len(list):返回列表list中的元素个数max(list):返回列表list中元素的最大值min(list):返回列表list中元素的最小值sum(list):返回列表list中所有元素的和
triangleSet = {1,3,6,10,15,21,28,36,45,55} |
4.6 嵌套组合数据
list = [[1,0,0],[0,1,0],[0,0,1]] #单位嵌套列表 |
nobel_prize_dict = {"物理学家":["伦琴","爱因斯坦","波尔"],"化学家":["欧内斯特·卢瑟福","范特霍夫","玛丽·居里"],"医学家":["埃米尔·阿道夫·冯·贝林","罗伯特·科赫","屠呦呦"]} |
4.7 典型案例
4.7.1 查找
查找:在指定的信息中寻找一个特定的元素
- 查找算法:如顺序查找算法、二分查找算法等
- 组合数据函数:如列表的list.index()函数等
🚀 顺序查找
顺序查找算法:将列表中的元素逐个与给定关键字比较
如果有一个元素与给定关键字相等,则查找成功;否则,查找失败顺序查找算法不要求列表中的元素是有序的,如果列表中有n个元素,顺序查找的最好情况是1,最坏情况是n,时间复杂度是O(n)
使用顺序查找算法查找给定关键字key在列表中是否存在
list1 = [3,6,1,9,5,8,7,4] |
🚀 二分查找
二分查找又称为折半查找,属于有序查找算法,即要求列表中的元素是升序或降序排列的
二分查找的基本思想(假设列表中的元素是按升序排列的)
- 将列表中间位置的元素与给定关键字key比较,如果两者相等,则查找成功;否则利用中间位置元素将列表分成前、后两个子列表
- 如果中间位置记录的元素大于key,则进一步查找前一子列表;否则进一步查找后一子列表
- 重复以上过程,直到找到满足条件的元素使查找成功,或直到子列表不存在为止,此时查找不成功
如果列表中有n个元素,二分查找的最好情况是1,最坏情况是[log2(n)]+1([log2(n)]指对log2(n)的结果取整),时间复杂度是O(log2(n))

def binary_search(key,list): |
4.7.2 排序
🚀 冒泡排序
重复地访问要排序的元素,依次比较相邻两个元素,如果顺序错误就把它们调换过来,直到没有元素需要交换,排序完成
- 比较相邻的元素,如果前一个比后一个大,就把它们两个调换位置
- 对每对相邻元素做同样的工作,从开始第一对到结尾的最后一对
- 针对所有的元素重复以上的步骤,除了最后一个
- 重复上面的步骤,直到没有任何一对数字需要比较

list1 = [8,3,1,5,2] |
🚀 选择排序
初始时在序列中找到最小(大)元素,放到序列的起始位置作为已排序序列,然后,从剩余未排序元素中继续寻找最小(大)元素,放到已排序序列的末尾,以此类推,直到所有元素均排序完毕

list1 = [8,3,1,5,2] |
4.7.3 推导式
推导式提供了创建组合数据的简单途径
推导式一般在 for 之后跟一个表达式,后面有零到多个for或if子句,返回结果是一个根据其后的 for 和 if条件生成的组合数据
通过推导式可以快速创建列表、元组、字典和集合等
列表推导式的一般格式为:
[表达式 for 变量 in 列表 [if 条件]],其中,if条件表示对列表中元素的过滤,可选元组、字典、集合等推导式的创建与列表创建类似,只需要将外层[]替换成相应的{}或()
使用推导式创建列表
[x ** 2 for x in range(6)] #[0, 1, 4, 9, 16, 25] |
使用推导式创建集合
list = [1,2,3,3,2,4] |
使用推导式创建字典
{i: i % 3 == 0 for i in range(1,11)} |
使用推导式创建元组
questionList = ['name','profession','favorites'] |
4.7.4 列表作为堆栈和队列使用
列表作为堆栈使用
list1 = [] |
列表作为队列使用,列表作为队列添加和删除元素
from collections import deque |
5 函数
5.1 函数定义和调用
🚀 函数定义
函数是组织好的、可重复使用的、用来实现单一或相关联功能的代码段
函数的使用能提高应用的模块性、代码的重用率和可读性Python提供了许多内建函数,如
input()、print()等函数,可以直接在程序中使用,当Python提供的内建函数不能满足要求时,需要用户自定义函数用户自定义函数的一般格式为:
def 函数名([参数1,参数2,…]): |
def myHello(): |
🚀 函数调用
函数定义完成后,就可以在程序中调用了,函数调用时需要指出函数名称,并传入相应的参数
函数调用时传入的参数称为实际参数,简称实参
在默认情况下,函数调用时传入的实参个数、顺序等必须和函数定义时形参的个数、顺序一致
函数调用时的执行顺序如下:
- 执行函数调用前的语句
- 执行函数调用,运行被调用函数内的语句,并返回相应结果
- 执行函数调用后的语句
定义一个求梯形面积函数并调用
#定义函数. |
5.2 函数参数
5.2.1 参数传递
定义一个函数Swap(x,y),实参为数字类型。在函数Swap(x,y)中交换2个形参的值,观察函数外面的实参变化情况
#定义函数 |
由此可见,和C++、JAVA同理,形参的改变不会影响实参
定义一个函数
changeList(myList),实参为列表。在函数调用中给列表myList添加了一个新元素,观察函数外面的实参变化情况
#定义函数 |
不可变类型:类似 C++ 的值传递,如整数、字符串、元组。如
fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a) 内部修改 a 的值,则是新生成一个 a 的对象可变类型:类似 C++ 的引用传递,如 列表,字典。如
fun(list),则是将 list 真正的传过去,修改后 fun 外部的 list 也会受影响
5.2.2 参数类型
🚀 必需参数
定义一个加法函数
myAdd(),使用必需参数传递参数
#定义函数. |
🚀 关键字参数
定义一个函数
stuInfo(),使用关键字参数传递参数
#定义函数. |
🚀 默认参数
定义一个函数
stuInfo(),使用默认参数传递参数
#定义函数. |
🚀 不定长参数
在实际应用中,有可能需要一个函数能处理比当初声明时更多的参数,这种参数称为不定长参数
不定长参数有如下两种形式:
*args:将接收的多个参数放在一个元组中**args:将显式赋值的多个参数放入字典中
定义一个求和函数
addFunc(),使用不定长参数传递参数
def addFunc(x,y,*args): |
5.2.3 参数传递的序列解包
def func(x,y,z): |
5.3 特殊函数
5.3.1 匿名函数
匿名函数是指没有函数名的简单函数,只可以包含一个表达式,不允许包含其他复杂的语句,表达式的结果就是函数的返回值。在Python中,使用关键字lambda创建匿名函数
创建匿名函数的一般格式为:
lambda [arg1[,arg2,…,argn]]: expression
arg1,arg2,…,argn:形参,可以没有,也可以有一个或多个expression:表达式
sum = lambda x,y: x + y |
5.3.2 递归函数
如果一个函数在函数体中直接或者间接调用自身,那么这个函数就称为递归函数
递归函数在执行过程中可能会返回以再次调用该函数
如果函数a中调用函数a自身,则称为直接递归
如果在函数a中调用函数b,在函数b中又调用函数a,则称为间接递归
求1+2+…+n的和来分析递归函数的原理和使用方法
如果用
fac(n)表示1+2+…+n的和,则
fac(n)= 1+2+…+n,fac(n-1)= 1+2+…+(n-1)…fac(2)= 1 + 2,fac(1)= 1$fac(n)\begin{cases}
& \text{ n+fac(n-1) } ,n>1 \
& \text{ 1 } ,n=1
\end{cases} $
根据
fac(n)的公式,可以定义如下的求和函数fac(n):
def fac(n): |
典中点再来一个爬楼梯问题,使用递归函数求斐波那契数列前20项之和
$fib(n)\begin{cases}
& \text{ fib(n-1)+fib(n-2) } ,n>2 \
& \text{ 1 } ,n=1或2
\end{cases} $
#定义求斐波那契数列第n项的函数 |
5.3.3 嵌套函数
- 嵌套函数指在一个函数(称为外函数)中定义了另外一个函数(称为内函数)
- 嵌套函数中的内函数只能在外函数中调用,不能在外函数外面直接调用
#定义外函数 |
#定义外函数 |
5.4 装饰器
5.4.1 装饰器的定义和调用
装饰器(Decorator)是Python函数中一个比较特殊的功能,用来包装函数的函数。可以使程序代码更简洁。
装饰器常用于下列情况:
- 将多个函数中的重复代码拿出来整理成一个装饰器
- 对多个函数的共同功能进行处理
定义装饰器的一般格式
def decorator(func): |
装饰器的定义和调用
#定义装饰器 |
使用装饰器修改网页文本格式
#定义装饰器 |
5.4.2 带参数的装饰器
使用带参数的装饰器检查函数参数合法性
#定义带参数的装饰器 |
5.5 变量作用域
Python中,不同位置定义的变量决定了这个变量的访问权限和作用范围。Python中的变量可分为如下4种
- 局部变量和局部作用域
L(Local):包含在def关键字定义的语句块中- 全局变量和全局作用域
G(Global):在模块的函数外定义的变量- 闭包变量和闭包作用域
E(Enclosing):定义在嵌套函数的外函数内、内函数外的变量- 内建变量和内建作用域
B(Built-in):系统内固定模块里定义的变量
5.5.1 全局变量和局部变量
全局变量和局部变量的使用
x = 100 #定义全局变量x |
5.5.2 global和nonlocal
使用关键字
global修改变量作用域
x = 100 #定义全局变量 |
使用关键字
nonlocal修改变量作用域
def outerFunc(): |
5.6 典型案例
5.6.1 加密和解密
将输入字符串的所有字符加密,密钥key为3。然后,再使用同样的密钥key对加密后的字符串进行解密
分析:
- 定义一个加密函数对传入的明文进行加密,返回加密后的密文
- 定义一个解密函数对传入的密文进行解密,返回解密后的明文
#加密函数 |
5.6.2 求最大公约数
求两个正整数的最大公约数
方法一:创建非递归函数求最大公约数
分析:非递归函数使用穷举法实现
- 将两个数m和n做比较,取较小的数作为smaller
- 以smaller为被除数分别和输入的两个数m和n做除法运算
- 被除数每做一次除法运算,值减少1,直到两个运算的余数都为0,该被除数为这两个数的最大公约数
#定义非递归函数 |
方法二:创建递归函数求最大公约数
分析:递归函数采用辗转相除法实现
- 取两个数中较大的数做除数,较小的数做被除数
- 用较大的数除较小的数:如果余数为0,则较小数为这两个数的最大公约数;如果余数不为0,则用较小数除上一步计算出的余数
- 重复上述步骤,直到余数为0,则这两个数的最大公约数为上一步的余数
#定义递归函数 |
方法三:使用Math中的函数求最大公约数
分析:直接调用Math中的
gcd()函数
import math |
5.6.3 使用装饰器检查函数参数合法性
使用装饰器检查函数参数合法性
#定义装饰器 |
5.6.4 模拟轮盘抽奖游戏
编写程序模拟轮盘抽奖游戏
分析:抽奖数字范围为1~100
- 抽中的数字在1~3范围,为特等奖,奖金为10000元
- 抽中的数字在4~10范围,为一等奖,奖金为5000元
- 抽中的数字在11~30范围,为二等奖,奖金为1000元
- 抽中的数字在31~100范围,为三等奖,奖金为300元
import random |
6 面向对象程序设计
6.1 概述
🚀 程序设计方法
- 计算机程序设计的语言有很多种,如C/C++、C#、Java和Python等
- 程序设计语言描述计算机系统的方式一般有两种:面向过程程序设计(Procedure Oriented Programming, POP)和面向对象程序设计(Object Oriented Programming,OOP)
- POP把计算机程序视为一系列命令的集合,即一组函数按照事先设定的顺序依次执行,函数是程序的基本单元
- 为了简化程序设计,把函数继续分解为子函数来降低程序的复杂度。使用POP的程序设计语言有C、Python等
- OOP是一种新的程序设计思想和方法。OOP把计算机程序视为一组对象(Object)的集合,每个对象都可以接收其他对象发送的消息,并处理这些消息。 计算机程序的执行指一系列消息在各个对象之间传递
- 支持OOP的程序设计语言有C++、C#、Java、Python等
- OOP的基本思想是,将数据以及对数据的操作封装在一起,组成一个相互依存、不可分割的整体,即对象
- 对相同类型的对象进行分类、抽象后,得出共同特征而形成类
- 面向对象程序设计的关键是,如何合理地定义和组织这些类及类之间的关系
- OOP的基本概念包括对象、类、消息、封装、继承和多态等。其中,封装、继承和多态是OOP最重要的三个特征
🚀 Python中的面向对象程序设计
Python不仅支持POP,更是一种面向对象、高级的动态编程语言,完全支持OOP的各项功能,如封装、继承、多态及对类方法的覆盖或重写等
Python中对象的概念很广泛,一切内容都可以看成对象
6.2 类与对象
6.2.1 类的定义
类是一种类型,对象是该类型的一个变量
类是抽象的,一般不占用内存空间;对象是具体的,创建一个对象时要为其特征分配相应的内存空间
定义类的一般格式为:
class 类名: |
- 组成:主要由类头和类体两部分组成
- 类头:由关键字class开头,后面是类的名称
- 类体:类体中包含类的实现细节,向右缩进对齐。类体中一般包含两部分内容
- 数据成员:用来存储特征的值(体现对象的特征),简称为成员
- 成员方法:用来对成员进行操作(体现对象的行为),简称为方法
- 类说明:类中也可以选择性添加类的文档字符串,对类的功能等进行说明(就是通过注释生成自己的一个API文档)
- 要使用类中定义的成员和方法,必须对类实例化,即创建类的对象
- 在Python中,使用赋值的方式创建类的对象,其一般格式为:
对象名 = 类名([参数列表])- 对象创建后,可以使用“对象.成员”“对象.方法()”调用该类的成员和方法
6.2.2 对象创建和使用
创建一个类的对象,调用类中的方法
#定义类 |
6.3 类的成员
6.3.1 成员类型
按照能否在类的外面直接访问,类的成员可分为如下两种
- 公有成员:公有成员不以下画线开头,在类的内部可以访问,在类的外面也可以访问
- 私有成员:以单下画线或双下画线开头,在类的外面不能直接访问,只能在类的内部访问或在类的外面通过对象的公有方法访问
在形式上,以单下画线或双下画线开头的是私有成员
_xxx:一个以下画线开头的成员。类和派生类可以访问这些成员__xxx:以两个或更多下画线开头但不能以两个或更多下画线结束的成员。对该成员,只有类自己可以访问,派生类也不能访问按照归属于类还是对象,类的成员可分为两类
- 类成员:定义在类体中且在所有方法外的成员为类成员。类成员属于类本身,一般通过类名调用,不建议使用对象名调用
- 实例成员:在类的方法中定义的成员为实例成员。实例成员只能被对象调用。实例成员一般在构造方法
__init__()中创建,或在其他方法中创建
创建及使用类的公有成员和私有成员
#定义类 |
类成员和实例成员的创建及使用
#定义类 |
动态添加类的成员
#定义类 |
6.3.2 内置成员
所有的类(无论是系统内置的类还是自定义类)都有一组特殊的成员,其前后各有两个下画线,是类的内置成员
__name__:类的名字,用字符串表示__doc__:类的文档字符串__bases__:由所有父类组成的元组__dict__:由类的成员组成的字典__module__:类所属模块
查看异常类Exception的内置成员
print("类的名字:",Exception.__name__) |
6.4 类的方法
6.4.1 方法类型
- 公有方法。公有方法的名字不以下画线开头,可以在类的外面通过类名或对象名调用
- 私有方法。私有方法以2个或更多下画线开头,可以在类的方法中通过self调用,不能在类的外面直接调用
- 静态方法和类方法。静态方法和类方法成员可以通过类名和对象名调用,但不能直接访问属于对象的成员,只能访问属于类的成员,不属于任何对象。静态方法使用装饰器
@staticmethod声明,类方法使用装饰器@classmethod声明- 抽象方法。抽象方法一般定义在抽象类中并要求派生类对抽象方法进行实现
#定义类 |
6.4.2 属性
- 属性:一种特殊形式的方法,结合了成员和方法的各自优点,既可以通过属性访问类中的成员,也可以在访问前对用户为成员提供数据的合法性进行检测,还可以设置成员的访问机制
- 属性通常包括get()方法和set()方法。前者用于获取成员的值,后者用于设置成员的值
- 除此之外,属性也可以包含其他方法,如删除方法
del()等
使用属性访问并检查私有成员值的合法性
#定义类. |
使用属性访问私有成员
#定义类 |
6.4.3 特殊方法
在Python中,类有大量的特殊方法,其中比较常见的是构造方法
__init__()和析构方法__del__()
- 构造方法
__init__()用来为类中的成员设置初始值或进行必要的初始化工作,在类实例化时被自动调用和执行- 析构方法
__del__()一般用来释放对象占用的资源,在删除对象和回收对象空间时被自动调用和执行
构造方法和析构方法的使用
#定义类 |
6.5 类的继承与多态
6.5.1 类的继承
继承类称为派生类或子类,被继承类称为父类或基类
在Python中,派生类可以继承一个父类(单继承)或多个父类(多继承)
当派生类继承多个父类时,多个父类之间用逗号隔开
创建派生类的格式为:
class 派生类(父类1,父类2,…): |
派生类可以继承父类的成员和方法,也可以定义自己的成员和方法
如果父类方法不能满足要求,派生类也可以重写父类的方法
类的单继承
#定义People类 |
类的多继承
#定义People类 |
6.5.2 类的多态
多态(Polymorphism):一般是指父类的一个方法在不同派生类对象中具有不同表现和行为
派生类在继承了父类的行为和属性之后,还可能增加某些特定的行为和属性,也可能会对继承父类的行为进行一定的改变,这些都是多态的表现形式
类的多态实现
#定义类Animal |
6.6 抽象类和抽象方法
抽象类往往用来表征对问题领域进行分析、设计中得出的抽象概念,是对一系列看上去不同但本质上相同的概念抽象
抽象类特点:抽象类中通常包含抽象方法(没有实现功能),该类不能被实例化,只能被继承,且派生类必须实现抽象类中的抽象方法
Python中一般使用抽象基类(Abstract Base Class,ABC)来实现抽象类
ABC主要定义了基本类和最基本的抽象方法,可以为派生类定义公有的API,不需要具体实现,相当于Java中的接口或抽象类
7 模块 包 库
7.1 前言
模块(Module):一个以.py 结尾的Python文件,包含了 Python 对象和语句
包(Package):Python模块文件所在的目录,并且在该目录下必须有一个名为_init_.py的文件
库(Library):具有相关功能的包和模块集合,如Python标准库、NumPy库等
7.2 常用标准库模块
7.2.1 Turtle
Turtle是Python内嵌的绘制线、圆及其他形状(包括文本)的图形模块
1.画布(Canvas)
画布是Turtle模块展开用于绘图的区域
- 使用
turtle.screensize()函数设置画布的一般格式为:turtle.screensize(width,height,bg),例如,turtle.screensize(600, 400, "black")设置画布的宽为600、高为400、背景颜色为黑色 - 使用
turtle. setup()函数设置画布的一般格式为:turtle.setup(width,height,startx,starty),例如,turtle.setup(width=800, height=600, startx=100, starty=100)设置画布宽和高分别为800和600,画布左上角顶点在窗口的坐标位置为(100,100)
2.画笔
(1) 画笔状态。Turtle模块绘图使用位置方向描述画笔的状态
(2) 画笔属性。画笔的属性包括画笔的颜色、宽度和移动速度等
turtle.pensize(width):设置画笔宽度width,数字越大,画笔越宽turtle.pencolor(color):设置画笔颜色color,可以是字符串如”red”、”yellow”,或RGB格式turtle.speed(speed):设置画笔移动速度speed,范围为[0,10]的整数,数字越大,画笔移动的速度越快
(3)绘图命令:操纵Turtle模块绘图有许多命令,通过相应函数完成。绘图命令通常分为三类:画笔运动命令、画笔控制命令和全局控制命令
使用Turtle模块绘制一个圆和一个填充的正方形
import turtle #导入模块 |
使用Turtle模块在画布上写文字
import turtle |
7.2.2 Random
🚀 random.random()函数
random.random()函数用于生成一个[0, 1)之间的随机浮点数,其一般格式为:random.random()
使用random.random()函数生成5个[0, 1)之间的随机浮点数
import random |
🚀 random.uniform()函数
random.uniform()函数用于生成一个指定范围内的随机符点数,其一般格式为:random.uniform(a,b)
使用random.uniform()函数生成指定范围的随机浮点数
import random |
🚀 random.randrange()函数
random.randrange()函数用于生成指定范围、指定步长的随机整数,其一般格式为:random.randrange([start],stop[,step])
使用
random.randrange()函数随机生成10个1~100范围的奇数添加到列表中
import random |
🚀 random.choice()函数
random.choice()函数的功能是从序列对象中获取一个随机元素,其一般格式为:random.choice(sequence)
使用random.choice()函数从列表中随机获取一个元素
import random |
🚀 random.shuffle()函数
random.shuffle()函数用于将一个序列对象中的元素打乱,其一般格式为:random.shuffle(sequence[,random])
import random |
🚀 random.sample()函数
random.sample()函数从指定序列对象中随机获取指定长度的片段,其一般格式为:random.sample(sequence,k)
使用random.sample()函数从列表中随机选择若干元素形成一个新列表
import random |
7.2.3 Time & Datetime
🚀 Time模块
Time模块主要用于时间访问和转换,提供了各种与时间相关的函数
import time |
🚀 Datetime模块
date类为日期类。创建一个date对象的一般格式为:
d = datetime.date(year,month,day)
from datetime import date |
Time类为时间类。创建一个time对象的一般格式为:
t = time(hour,[minute[,second,[microsecond[,tzinfo]]]])
from datetime import time |
Datetime类为日期时间类。创建一个datetime对象的一般格式为:
dt = datetime(year,month,day,hour,minute,second,microsecond,tzinfo)
from datetime import datetime |
timedelta对象表示两个不同时间之间的差值。
td = datetime.timedelta(days,seconds,microseconds,milliseconds,hours,weeks)
from datetime import datetime,timedelta |
7.2.4 Os
🚀 获取平台信息
使用Os模块的一些属性和方法可以获取系统平台的相关信息
os.getcwd():获取当前工作目录os.sep:查看操作系统特定的路径分隔符os.linesep:查看当前平台使用的行终结符os.pathsep:查看用于分割文件路径的字符串os.name:查看当前系统平台os.environ:查看当前系统的环境变量
使用Os模块获取系统相关信息
import os |
🚀 目录、文件操作
os.mkdir(newdir):创建新目录newdiros.rmdir(dir):删除目录diros.listdir(path):列出指定目录path下所有文件os.chdir(path):改变当前脚本的工作目录为指定路径pathos.remove(file):删除一个指定文件fileos.rename(oldnam,newname):重命名一个文件
使用Os模块对目录、文件进行操作
import os |
使用os.path模块获取文件属性
import os |
🚀 调用系统命令
os.popen(cmd[, mode[, bufsize]]):用于由一个命令打开一个管道os.system(shell):运行shell命令
使用Os模块中的函数调用系统命令
import os |
7.2.5 Sys
使用Sys模块获取系统信息
import sys |
7.2.6 Timeit
Timeit模块是一个具有计时功能的模块,常用于测试一段代码的运行时
Timeit模块常用的函数有timeit()和repeat()函数
timeit()函数返回执行代码所用的时间,单位为秒,其一般格式为:t = timeit(stmt='code',setup='code',timer=<defaulttimer>,number=n)
repeat()函数比timeit()函数多了一个repeat参数,表示重复执行指定代码这个过程多少遍,返回一个列表表示执行每遍的时间;其一般格式为:t = repeat(stmt='code',setup='code',timer=<defaulttimer>,repeat=m,number=n)
测试函数myFun()中代码的执行时间
import timeit |
7.2.7 Zlib
使用Zlib模块对字符串进行压缩和解压缩
import zlib |
7.3 第三方库
7.3.1 NumPy
NumPy是基于Python的一种开源数值计算第三方库,它支持高维数组运算、大型矩阵处理、矢量运算、线性代数运算、随机数生成等功能
🚀 数组
NumPy库中的ndarray是一个多维数组对象。该对象由两部分组成:实际的数据和描述这些数据的元数据。和Python中的列表、元组一样,NumPy数组的下标也是从0开始
🚁 创建数组
在NumPy库中,创建数组可使用np.array()函数,其一般格式为:numpy.array(object,dtype=None,copy=True,order=None,subok=False,ndmin=0)
- object为数组或嵌套的数列
- dtype为数组元素的数据类型
- copy指定对象是否需要复制
- order为创建数组的样式,C为行方向,F为列方向,A为任意方向(默认)
- subok指定默认返回一个与基类类型一致的数组
- ndmin为指定生成数组的最小维度
创建数组
import numpy as np |
创建特定数组
import numpy as np |
🚁 数组索引和切片
import numpy as np |
查看数组属性
import numpy as np |
数组操作
import numpy as np |
数组运算
import numpy as np |
🚀 矩阵
在NumPy中,通常使用mat()函数或matrix()函数创建矩阵,也可以通过矩阵的转置、逆矩阵等方法来创建矩阵
创建矩阵
import numpy as np |
矩阵运算
import numpy as np |
7.3.2 Pandas
Pandas是基于NumPy库的一种解决数据分析任务的工具库
Pandas库的主要功能有:创建Series(系列)和DataFrame(数据帧)、索引选取和过滤、算术运算、数据汇总和描述性统计、数据排序和排名、处理缺失值和层次化索引等
Pandas库下载网址:https://pypi.org/project/pandas/#files。
🚀 系列(Series)
系列与NumPy库中的一维数组(array)类似,能保存字符串、Bool值、数字等不同的数据类型
创建一个系列的一般格式为:pandas.Series(data,index,dtype,copy)
- data:数据,采取各种形式,如ndarray、list、constants等
- index:索引值,必须是唯一的和散列的
- dtype:数据类型
- copy:复制数据,默认为False
import pandas as pd |
从字典创建一个系列
import pandas as pd |
🚀 数据帧(DataFrame)
数据帧是二维的表格型数据结构,即数据以行和列的表格方式排列。与系列相比,数据帧使用得更普遍
创建一个数据帧的一般格式为:pandas.DataFrame(data,index,columns,dtype,copy)
- data:数据,可以是各种类型,如ndarray、series、lists、dict、 constant或DataFrame等
- index,columns:分别为行标签和列标签
- dtype:每列的数据类型
- copy:复制数据,默认值为False
从列表创建DataFrame
import pandas as pd |
DataFrame的创建和访问
import numpy as np |
7.3.3 SciPy
SciPy库是一款方便、易于使用、专为科学和工程设计的工具库,包括统计、优化、整合、线性代数、傅里叶变换、信号和图像处理、常微分方程求解等
🚀 SciPy库的使用
SciPy库中的模块很多,不同模块的功能相对独立:
- scipy.constants(数学常量)
- scipy.fftpack(快速傅里叶变换)
- scipy.integrate(积分)
- scipy.optimize(优化算法)
- scipy.stats(统计函数)
- scipy.special(特殊数学函数)
- scipy.signal(信号处理)
- scipy.ndimage(N维图像)
🚁 constants模块
查看constants模块中常用数学常量
from scipy import constants as con |
🚁 special模块
使用special模块完成特殊数学函数功能
from scipy import special as sp |
🚁 scipy.linalg模块
计算方阵的行列式和逆矩阵
import numpy as np |
信号处理模块signal
import numpy as np |
7.3.4 Matplotlib
Matplotlib是一个基于Python、跨平台、交互式的2D绘图库,以各种硬拷贝格式生成出版质量级别的图形
🚀 Matplotlib库的使用
使用plot()函数绘制图形并设置坐标轴
import matplotlib.pyplot as plt |
使用figure()函数画绘制多幅图形
import numpy as np |
使用matplotlib.pyplot绘图并设置图例
import matplotlib.pyplot as plt |
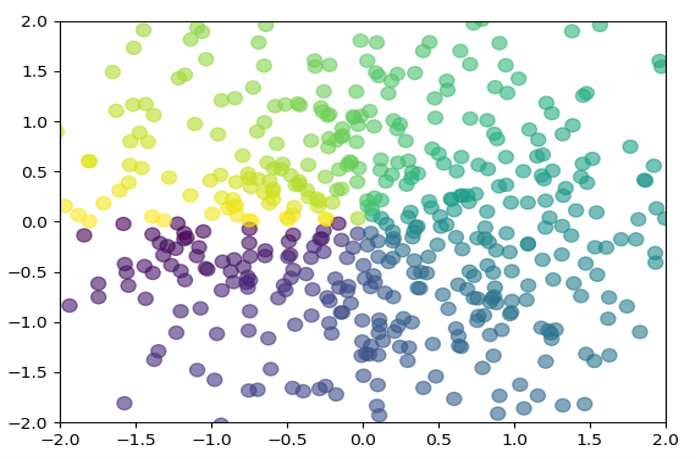
使用scatter ()函数绘制散点图
import numpy as np, matplotlib.pyplot as plt |
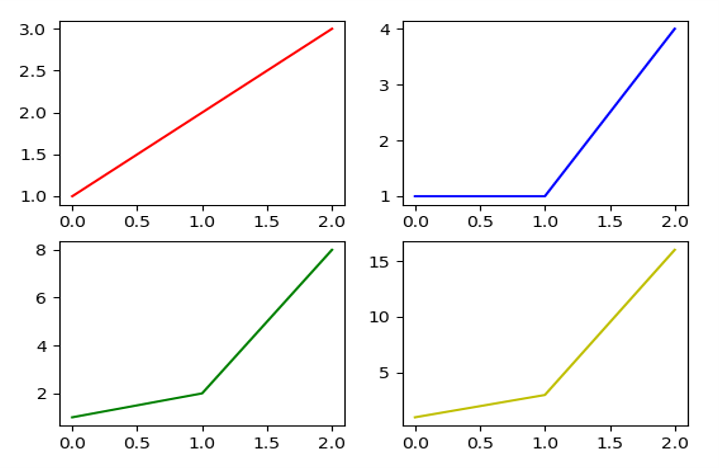
使用subplot()函数绘制多个子图
import matplotlib.pyplot as plt |
7.3.5 Jieba
Jieba库支持三种分词模式
- 精确模式:把文本精确地切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,存在冗余
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,存在冗余
- Jiaba分词还支持繁体分词和自定义分词
在命令行界面中执行命令pip install jieba,下载库
🚀 Jieba库的使用
🚁 分词
可使用方法 jieba.cut()和jieba.cut_for_search()对中文字符串进行分词
- string:需要分词的中文字符串,编码格式为Unicode、UTF-8或GBK
- cut_all:是否使用全模式,默认值为 False
- HMM:是否使用 HMM 模型,默认值为 True。
方法jieba.cut_for_search()和jieba.lcut_for_search()接收2个参数
- string:需要分词的中文字符串,编码格式为Unicode、UTF-8或GBK
- HMM:是否使用HMM模型,默认值为 True
import jieba |
🚁 关键词提取
Jieba库采用“词频-逆向文件频率” 算法进行关键词抽取。jieba.analyse.extract_tags(sentence,topK=20,withWeight=False,allowPOS=())
- sentence为待提取的文本
- topK为返回若干个TF/IDF权重最大的关键词,默认值为20
- withWeight为是否返回关键词权重值,默认值为False
- allowPOS指定仅包括指定词性的词,默认值为空,即不筛选
使用Jieba库提取中文字符串中的关键词
import jieba |
🚁 词性标注
Jieba库支持创建自定义分词器,方法如下:jieba.posseg.POSTokenizer(tokenizer=None)
,tokenizer指定内部使用的jieba.Tokenizer分词器,jieba.posseg.dt 为默认词性标注分词器
import jieba.posseg as pseg |
7.3.6 PyInstaller
Pyinstaller库可以用来打包Python应用程序。打包时,Pyinstaller库会扫描Python程序的所有文档,分析所有代码找出代码运行所需的模块,然后将所有这些模块和代码放在一个文件夹里或一个可执行文件里。用户就不用下载各种软件运行环境,如各种版本的Python和各种不同的包,只需要执行打包好的可执行文件就可以使用软件了
下载与安装:在命令行界面中执行命令pip install pyinstaller
🚀 打包Python程序
创建一个Python源文件test1.py
import random |
打开命令行界面,进入源文件test1.py所在路径
在命令行界面中运行命令
pyinstaller-F test1.py打包源文件成功执行命令后,生成的可执行文件test1.exe在源文件test1.py所在路径的文件夹dist
7.4 自定义模块
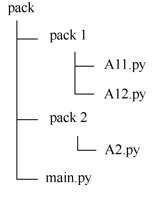
🚀 [场景1] 在源文件A11.py中调用包pack1中的模块A12
在本场景中,源文件A11.py和模块A12在同一路径。实现步骤为:
在pack1文件夹下添加文件
__init__.py分别编写源文件A11.py和模块A12中的程序代码
#模块A12中的程序代码 |
#方法一 源文件A11.py中的程序代码 |
#方法二 源文件A11.py中的程序代码 |
#方法三 源文件A11.py中的程序代码 |
#方法四 源文件A11.py中的程序代码 |
🚀 [场景2] 在源文件main.py中调用包pack2中的模块A2
本场景中,源文件main.py和模块A2所在的包pack2在同一路径。实现步骤为:
- 在pack2文件夹下添加文件
__init__.py - 分别编写模块A2和源文件main.py中的程序代码
#模块A2中的程序代码 |
#方法一 源文件main.py中的程序代码 |
#方法二 源文件main.py 中的程序代码 |
🚀 [场景3] 在源文件A11.py中调用模块A2
在本场景中,源文件A11.py和模块A2分别在两个不同路径的包pack1和pack2中。实现步骤为:
- 在pack2文件夹下添加文件
__init__.py - 分别编写源文件A11.py和模块A2中的程序代码
#模块A2中的程序代码 |
#方法一 源文件A11.py中的程序代码 |
#方法二 源文件A11.py中的程序代码 |
7.5 典型案例
7.5.1 使用Turtle绘制表面填充正方体
分析:
- 从视角上看正方体一般只能看到三个面,正立面、顶面和右侧面
- 只需要对这三个面(分别为填充红色、绿色和蓝色)进行绘制和填充即可
import turtle #导入模块 |
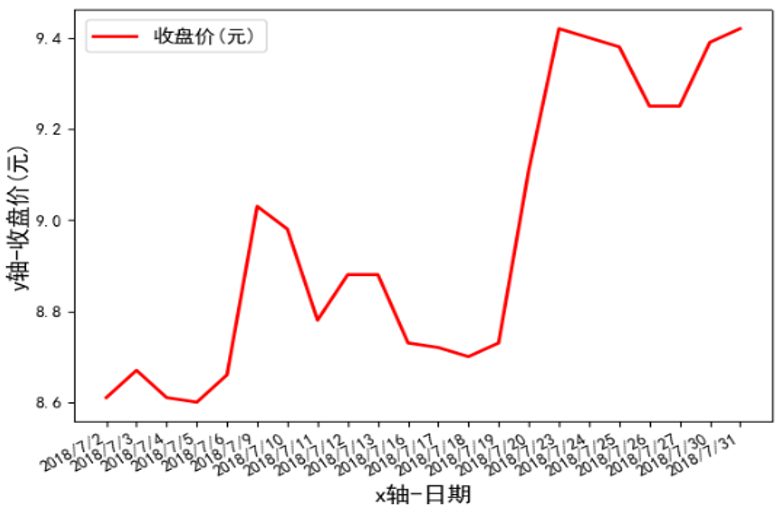
7.5.2 使用NumPy和Matplotlib分析股票
使用NumPy和Matplotlib对股票000001(平安银行)在2018年7月的交易数据进行分析并显示股票收盘价走势图
分析:股票000001(平安银行)在2018年7月的交易数据存储在文件000001_stock01.csv中(可从网站资源中下载),数据各列分别是date(日期)、open(开盘价)、high(最高价)、close(收盘价)、low(最低价)、volume(成交量)。股票000001在2018-07-2~2018-07-6的交易数据如下所示:
2018/7/2, 9.05, 9.05, 8.61, 8.55, 1315520.12
2018/7/3, 8.69, 8.7, 8.67, 8.45, 1274838.5
2018/7/4, 8.63, 8.75, 8.61, 8.61, 711153.38
2018/7/5, 8.62, 8.73, 8.6, 8.55, 835768.81
2018/7/6, 8.61, 8.78, 8.66, 8.45, 988282.75
- 使用NumPy对股票文件进行处理需要先将股票交易文件000001_stock01.csv中的不同列数据分别读到多个数组中保存
- 使用numpy.mean()函数计算收盘价和成交量的算术平均值
- 使用numpy.average()函数计算收盘价的加权平均价格
- 使用numpy.max()函数、np.min()函数分别计算股票最高价、最低价
- 使用numpy.ptp()函数计算股票最高价波动范围、股票最低价波动范围
- 使用matplotlib.pyplot中的相关函数绘制了股票000001在2018年7月的收盘价走势图
import numpy as np,os |
7.5.3 使用Pandas分析股票交易数据
使用Pandas对股票000001(平安银行)在2018年7月的交易数据进行统计分析
分析:
文件名为000001_stock02.csv(可从网站资源下载)。为了适应Pandas要求,为文件中各列数据添加了对应的列名
Date, open, high, low, close, volume
2018/7/2, 9.05, 9.05, 8.61, 8.55, 1315520.12
2018/7/3, 8.69, 8.7, 8.67, 8.45, 1274838.5
2018/7/4, 8.63, 8.75, 8.61, 8.61, 711153.38
2018/7/5, 8.62, 8.73, 8.6, 8.55, 835768.81
2018/7/6, 8.61, 8.78, 8.66, 8.45, 988282.75
- 使用Pandas中的pd.loc()函数、pd.count()函数对文件000001_stock02.csv中的股票数据进行筛选计数
- 使用NumPy中的np.where()函数结合在Pandas中获取的列数据对股票数据进行分组
- 调用Pandas中的pd.describe()函数对股票数据进行描述性统计
- 调用Pandas中的pd.corr()函数分别对股票数据进行相关性分析
import pandas as pd |
7.5.4 使用图像处理库处理和显示图像
分析:
- 使用imageio库中的imread()函数读取图像文件
- 获取图像的数据类型和图像大小
- 使用imageio库中的imwrite()函数等修改图像颜色、图像大小,裁减图像
- 使用matplotlib.pyplot和matplotlib.image库中的相关函数绘制原始图像
import imageio,os,numpy |

9 文件的访问
9.1 概述
- 文件:存储在外部存储器上的数据集合
- 文件名:由基本名和扩展名组成,不同类型的文件扩展名也不相同
例如,文本文件的扩展名为.txt,Word文档的扩展名一般为.docx,可执行文件的扩展名一般为.exe,C语言源文件的扩展名为.c等
按文件内容分类
- 程序文件:存储程序,包括源文件和可执行文件:如Python源文件(扩展名为.py)、C++源文件(扩展名为.cpp)、可执行文件(扩展名为.exe)等都是程序文件
- 数据文件:存储程序运行所需要的各种数据: 如文本文件(.txt)、Word文档(.docx)、Excel工作簿(.xlsx)等
按信息存储形式分类
- 文本文件:文本格式文件(.txt)、网页文件(.html)等
- 二进制文件:常见的二进制文件有数据库文件、图像文件、可执行文件和音频文件等
9.2 文本文件访问
9.2.1 打开文件
在Python中,访问文本文件可以分为三步
- 用
open()函数打开一个文件,返回一个文件对象 - 调用文件对象中的函数对文件内容进行读或写等操作
- 调用文件对象的close()函数关闭文件
🚀 open()
open()函数:
open(filename[,mode]),w写,r读,a追加。其中w写会覆盖原来内容
file = open(r"d:\data1.txt","w") #打开一个文件用于写入 |
🚀 with-as
with open(filename[,mode]) as file: |
file为open()函数返回的文件对象
- 简化程序代码
- 自动释放和清理相关资源
使用with-as语句访问文本文件
with open("d:/data2.txt","w") as file: |
9.2.2 文件操作
🚀 写文件
- file.write()函数:
file.write(str) - file.writelines()函数:
file.writelines(sequence),sequence为要写入的字符序列
使用
file.write()函数向文件中写入字符串
with open("Shakespeare.txt","w") as file: |
紧接着 打开上一段中的结果文件Shakespeare.txt,并向文件中追加新的内容
str = input("请输入内容:") |
使用
file.write()函数向文件中写入元组
mingTuple = ("王阳明","于谦","戚继光","海瑞","郑和","徐达") #明朝著名人物 |
Ming.txt文件内容:‘王阳明‘,‘于谦‘,‘戚继光‘,‘海瑞‘,‘郑和‘,‘徐达‘
使用
file.writelines()函数向文件中写入字符序列
str = ["好雨知时节,当春乃发生。\n","随风潜入夜,润物细无声。"] |
好雨知时节,当春乃发生。
随风潜入夜,润物细无声。
🚀 读文件
- file.read()函数:
file.read([size]),当size被忽略或为负时,则该文件的所有内容都将被读取且返回,返回一个序列(即上一个例子好雨知时节中的str) - file.readline()函数:
file.readline([size]),读取一行,size有参时返回的是前x个字符保存到列表中 - file.readlines()函数:
file.readlines(),返回多行,file.readlines([sizeint])
使用
file.read()函数读取Shakespeare.txt的内容如果出现报错**’gbk’ codec can’t decode byte 0xa4 in position 4: illegal multibyte sequence**,
with open("文件路径","模式",encoding='UTF-8'),加上编码格式
with open("Shakespeare.txt","r") as file: |
使用for语句读取文件Shakespeare.txt的内容
with open("Shakespeare.txt","r") as file: |
使用
readline()函数读取Shakespeare.txt的一行内容
with open("Shakespeare.txt","r") as file: |
使用
readlines()函数读取文件Shakespeare.txt的内容
with open("Shakespeare.txt","r") as f: |
🚀 其它文件操作
- file.close():关闭文件
- file.flush():刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件
- file.fileno():返回一个整型的文件描述符(file descriptor,FD,整型)
- file.isatty():如果文件连接到一个终端设备则返回True,否则返回 False
- file.tell():返回文件当前位置
- file.seek():重定位文件对象的指针位置
- file.truncate([size]):从文件的首行首字符开始截断,截断文件为size个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除
使用函数
file.tell()和file.seek()重定位文件Shakespeare.txt
with open("Shakespeare.txt","r") as file: |
一个字符连个字节,“黑夜无论怎样悠长\n”,2*9=18
9.3 二进制文件访问
9.3.1使用Pickle模块读/写二进制文件
- 序列化:是指把内存中的数据对象在不丢失其类型的情况下转换成对应的二进制信息的过程
- 反序列化: 是指把序列化后的二进制信息准确无误地恢复到原来数据对象的过程
同文本文件访问过程相似,二进制文件访问也分为三个步骤
- 打开二进制文件
- 访问二进制文件
- 关闭二进制文件
在Python中访问二进制文件的常用模块有Pickle、Struct、Marshal和Shelve等
Pickle模块用于序列化和反序列化的函数有两个:pickle.dump()和pickle.load()函数
- pickle.dump()函数:
pickle.dump(data,file[,protocol]) - pickle.load()函数:
pickle.load(file)
使用
pickle.dump()函数向二进制文件中写入数据,注意模式是”wb”,特指二进制
import pickle |
使用
pickle.load()函数读取二进制文件中的内容,注意模式”rb”
import pickle |
9.3.2使用Struct模块读/写二进制文件
struct.pack(fmt,data1,data2, …):fmt为给定的格式化字符串。data1、data2为要写入的数据对象struct.unpack(fmt, string):fmt为给定的格式化字符串。string为要反序列化的字符串
使用
struct.pack()函数向二进制文件中写入数据
import struct |
使用
struct.unpack()函数读出二进制文件中的内容
import struct |
9.3.3使用Marshal模块读/写二进制文件
- marshal.dump()函数:
marshal.dump(data,file),data为待序列化的数据对象。file为创建或打开的文件对象 - marshal.load()函数:
marshal.load(file),file为打开的二进制文件对象
使用marshal.dump()函数向二进制文件中写入数据
import marshal |
使用
marshal.load()函数读出二进制文件中的内容
import marshal |
9.3.4使用Shelve模块读/写二进制文件
Shelve模块提供一种类似字典的方式操作二进制文件的功能,Shelve提供一个简单的数据存储方案,只有一个open()函数,open()函数接收一个文件名作为参数,返回一个shelf对象,格式:shelve.open(filename, mode, protocol=None, writeback=False)
- filename:打开或创建的二进制文件
- mode:文件打开模式
- protocol:序列化模式,可以是1或2,默认值为None
- writeback:是否将所有从二进制文件中读取的对象存放到一个内存缓存
使用Shelve模块向二进制文件中写入数据
import shelve |
使用Shelve模块读出二进制文件中的内容
import shelve |
使用Shelve模块修改二进制文件中的内容
import shelve |
9.4 典型案例
9.4.1 合并文件
合并指定路径下的联系人文件,要求没有重复的联系人信息
分析:在指定路径下有3个联系人文件contacts01.txt、contacts02.txt和contacts03.txt,3个联系人文件中的联系人信息有重复之处,需要合并,方法如下
- 获取并创建指定路径下的联系人文件列表fileList
- 创建保存联系人的联系人信息列表tempList和联系人信息文件contacts.txt
- 对fileList中的文件file进行遍历:如果file中指定行的联系人信息不在tempList中,则说明联系人信息没有重复,添加到tempList中,写入文件contacts.txt中;否则,不添加到tempList中,也不写入文件contacts.txt中
- 如果发生异常,则进行处理,并给出提示信息
import os,sys,re |
9.4.2 CSV文件操作
- CSV (Comma Separated Values,逗号分隔值)文件是一种常用的文本格式文件,用以存储表格数据,包括数字、字符等
- 很多程序在处理数据时都会使用CSV文件,其使用非常广泛
- Python内置了Csv模块来处理CSV文件
- Csv模块中用于文件处理的常用函数如下
- csv.writer(csvfile):返回一个writer对象。csvFile为打开的CSV文件对象
- writer.writerow(row):向CSV文件中写入一行数据
- writer.writerows(rows):向CSV文件中一次写入多行数据
- csv.reader(csvFile):返回一个reader对象,可通过迭代读取其中的内容。csvFile为打开的CSV文件对象
【例】 对CSV文件进行读/写操作
- 打开(或创建)salary.csv文件,通过Csv模块中的csv.writer()函数将返回的文件对象file转换为writer对象fw
- 调用fw.writerow()函数向CSV文件中写数据(包括标题和行数据)
- 打开salary.csv文件,通过Csv模块中的csv.reader()函数将返回的文件对象file转换为reader对象fr
- 从reader对象fr中读取数据
程序代码: |
 wechat
wechat alipay
alipay
